
OpenAI Researchers Have Discovered Why Language Models Hallucinate
A review of OpenAI's latest research paper

It is a truth universally acknowledged that an AI company in possession of a good GPU rack must be in want of solving hallucinations. And how could it be otherwise, for there is a crown awaiting to be claimed—the crown of the most promising market of the modern era, no less—by that who manages to build a chatbot that doesn't make stuff up when it doesn't know the answer. So it may come as a surprise that, despite three long years having passed since OpenAI released ChatGPT, the industry has only achieved a moderate reduction in the rate of failure, woefully inadequate for AI to be integrated into serious workflows across the economy.
Why do hallucinations happen, and why is it so hard to solve them? It is precisely OpenAI that may have found an answer to this elusive question. In a new research paper published last week titled "Why Language Models Hallucinate" (here’s the blog post), the authors make a fundamental claim: “language models hallucinate because standard training and evaluation procedures reward guessing over acknowledging uncertainty.” The idea isn’t new; the novelty lies in their claim that adjustments to training and evaluation could fix it. Just like a kid would try their luck guessing in a multiple-choice exam, language models (LMs) have been taught to do the same. Hallucinations are, then, not a feature but a mismatch between the training approach—getting more answers right is better—and a practical goal—do not lie to users.
Before we get to the details, let me do a quick meta-analysis of the paper, because, besides being an interesting study, it is three other things:
It is OpenAI's implicit admission that hallucinations deserve priority status; maybe CEO Sam Altman has internalized that he shouldn't promise AGI while America’s economy hangs by a thread if he doesn't yet have a means to raise AI's floor of value as much as he’s raised the ceiling.
The simplicity of the findings reveals that not enough money has been devoted industry-wide to understanding this issue; although hallucinations have been touted as AI's Achilles' heel, they don't get precedence over competitive concerns (it is the urge to beat other industry players that has delayed taking genuine care of this problem).
We may be closer than ever to getting AI products that don’t hallucinate; imagine how valuable ChatGPT would be if you were certain by default that it always says the truth (or, at least, it doesn’t lie, in favor of expressing confident ignorance, like “I don’t know”). I wouldn’t blink at AI being endlessly dressed up with words like “revolutionary.”
But let's get to the paper; it is worth looking closely at what OpenAI researchers found, how they believe this overdue annoyance can be better addressed, and what future work is yet to be done.
One thing I appreciate about the study right away is that the authors insist on demystifying hallucinations. It is counterproductive to believe they're inherent to AI, or even LMs, or that they're actually a good thing (like in dreams or reveries, where making stuff up is a feature, not a bug), so we shouldn't try to solve them. In some sense, the fact that hallucinations are so persistent may indicate that we're trying to make this technology something it isn't—LMs always hallucinate so let's find something else that doesn't!—but the practical implications of this is that you'd be swapping a bounded engineering problem (fix this thing into what you want) for an unbounded scientific problem (find some other thing that doesn't hallucinate by default). Of course, OpenAI researchers can't afford to believe this issue requires some unpredictable Eureka moments—which you can't buy—but I happen to agree with them: let's do our best with what we've been given; after all, for 70 years, AI has resembled alchemy more than chemistry, so what's a few more?
The authors start by assessing the origin of hallucinations, where they come from, and why they emerge in the first place. Some people believe that either bad-quality data or the wrong architecture is the culprit. However, according to them, the errors in the training dataset and those specific to the transformer architecture are, at most, a multiplier of the actual sources, which are 1) the pre-training objective (learn the language distribution over data to predict the next word) and 2) the post-training objective (minimize the number of wrong responses, e.g., on evaluation benchmarks).
If you asked an hypothetical LM trained on error-free data (unrealistic, but bear with me) to answer something that is not embedded in some legible pattern or not in the dataset at all, it still wouldn't say "I don't know" because it's been taught 1) to predict what comes next even if it hasn't encoded any patterns (or has encoded imperfect ones) and 2) that guessing, on average across many attempts, produces higher accuracy due to lucky hits, which makes the LM prone to plausible bluffs and guesses with an overconfidence unbefitting its limited knowledge. The problem comes, thus, not just from the data or the architecture (they can be aggravating factors), but from the misalignment of pre-training and post-training objectives.
How can this be addressed? In practice, the solution consists of reducing the importance and prevalence during post-training of evaluation benchmarks that measure performance solely as a function of response accuracy (e.g., GPQA, MMLU, MATH), or, conversely, modifying them so that they don't penalize abstaining, uncertainty, and "not knowing." As the authors explain, human students eventually learn the value of admitting ignorance "in the school of hard knocks," whereas LMs forever exist in "test-taking mode" and never learn the lesson. (Unfortunately, system prompts, custom instructions, and prompt engineering are of little use here.)

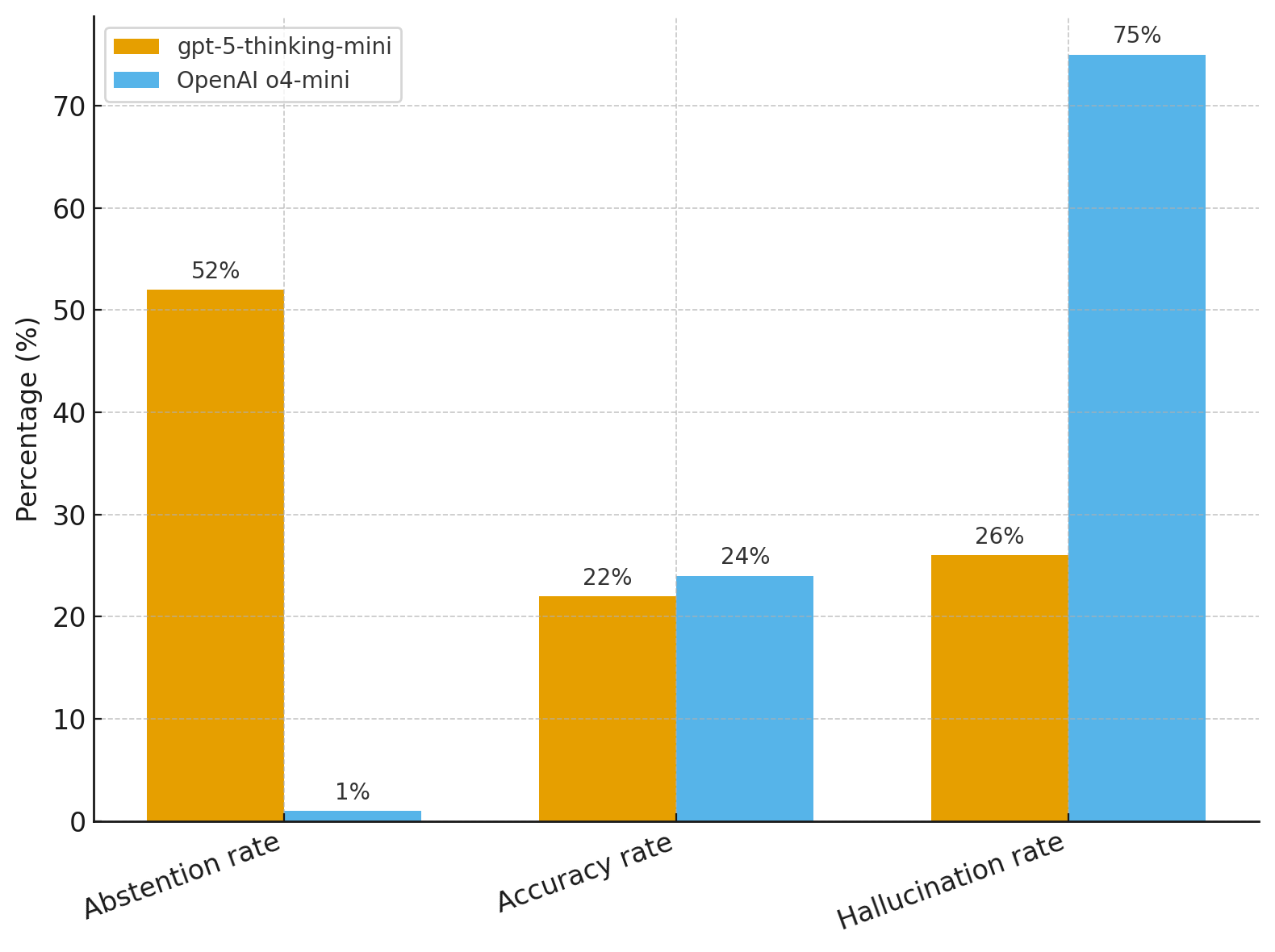
I want to include here a short aside. There's a big problem the authors only touch in passing, which is known by "out of distribution" (OOD): when the training data and the test data belong to different distributions—different from bad-quality data or misaligned training objectives—the LM will fail to extrapolate; this is a common occurrence in real-world settings and edge cases, which creates huge bottlenecks for integration in existing work processes.
One funny recent example of OOD I've seen is a variation of the mother surgeon riddle. The original version goes like this: a father and his son have a terrible car accident, and the father dies. When the boy arrives at the hospital, the surgeon looks at him and says, “I can’t operate on this kid, he is my son.” How is it possible? The correct answer, which trips people up, is that the surgeon is the mother (assumptions and prejudices and whatnot). But in the AI-tricking version, the prompt reveals the mother is the one who dies in the accident, so the parent rejecting doing surgery on the kid is the father. LMs get the counter-intuitive version right because they’ve seen it many, many times in the training data, but they get this straightforward version wrong because, regardless of how easy it seems to humans, they’ve never seen this enunciation (that’s the OOD), which leads them to hallucinating unhinged solutions (e.g., the surgeon is the boy’s other mother!); they try to fit their existing knowledge, i.e., “this riddle plays on stereotypes and biases about who’s likely to be a surgeon” in the context of a new version that lives out of the distribution (doesn’t play on gender roles).
That example is useful but also a simplification; OOD can take many forms, and it’s been a matter of serious research since before the modern deep learning revolution (circa 2012). Until the general form of OOD problems is solved, I don't think hallucinations will be reduced in any meaningful sense (I’m inclined to equate this form of hallucination with the elusive unknown unknowns: even if you learn to say “I don’t know,” you can’t know you don’t know what you don’t know). Unfortunately, unlike the other causes highlighted above, this doesn't depend on things researchers can modify; navigating reality is, by definition, an OOD problem that requires capabilities LMs lack, like intuition, fluid intelligence, improvisation, and generalization—and not even then can you ensure 100% performance (look at humans!).
But still, there's a lot to gain from reshaping the evaluation landscape to take into account how post-training objectives reinforce hallucinations instead of reducing them. The authors argue that, "under binary grading [right vs wrong; without consideration for clarification requests, or admissions of ignorance], abstaining is strictly sub-optimal.” (They make the case that this problem is of a socio-technical nature because not only do evaluation benchmarks need an overhaul, but the changes need to be broadly adopted by the industry and the "influential leaderboards." How do you entice AI companies to adopt a new way of doing things (friction) that will underscore the flaws in their technology (bad optics) when the field has transformed into a market (competitive pressures rule)? Let's not underestimate variables that, in being hard to measure, are often dismissed by tech types.)
The authors suggest including direct penalties for incorrect answers (instead of indirect penalization for abstaining) as an integral feature of evaluations (multiple-choice college exams often do this to prevent students from guessing).
This has been extensively studied in hallucination research, so they propose additions (that’s the paper’s main contribution): 1) the penalty must be explicit, in the prompt or test instructions, and 2) instead of applying this idea to hallucination-specific benchmarks (I focused my GPT-5 review on this), it should be integrated directly into popular benchmarks like SWE-bench or GPQA. (Note that evaluations like ARC-AGI are designed in a way that makes guessing mostly unfruitful, but it's not always possible to embed anti-guessing mechanisms in the benchmark design, in which case the authors' proposal is promising.) The intended behavior would be that LMs that are unsure of the correct answer are rewarded (or rather, less indirectly penalized) by saying "I don't know." Even if this doesn't get rid of hallucinations for good (due to the OOD problem mentioned above), it would bring LM's behavior in uncertain situations closer to what adult humans (who are not students) do.
The authors consider a few limitations of this approach, which I will express here in the form of rhetorical questions: What happens when an LM outputs not a plausible falsity but a nonsensical string of characters? What happens when the user asks an open-ended question like "write an essay about the difficulty of solving hallucinations"? What happens when the user omits context that is shared among humans by virtue of existing in the physical world but that remains inherently alien for LMs living in the cloud? What happens when "I don't know" proves valid for expressing uncertainty, but the user requires a more precise measure of confidence? What happens when being more explicit about degrees of confidence makes the answer sound inhuman (or rather nerd-like)?
All in all, hallucinations have proven to be a steep hill to climb; there are many loose ends to this approach, some fundamental issues need to be addressed (like OOD), and then there's the question of what trade-offs are worth engaging in for AI companies, including OpenAI. I see hallucinations as the final hurdle keeping LMs and generative AI from earning the status of worthwhile technology. I've insisted elsewhere and will insist here again: for the vast majority of humans individually, and for humanity as a whole, it is more important that the AI industry focuses on raising the floor of capabilities rather than the ceiling; no AGI is dumb at times.
To me the whole paper feels like a giant cope. "Look, it's not the technology that's broken, it's the evaluations."
And yet 90% of people using these things don’t know how often they are wrong. Sigh.