
GPT-5 Is Here: There's Only One Feature Worth Writing About
My short review of OpenAI’s new flagship model

OpenAI GPT-5 is out. I didn’t get the embargo because I’m a bit hard on OpenAI at times (which I think is good), but I’ve read all the early reviews: from Ethan Mollick, Tyler Cowen, Every, Latent Space, METR, Artificial Analysis, and a couple of others. I’ve watched the 1-hour-long demo, read the four blog posts that OpenAI put out, and the model’s system card PDF.
I can summarize GPT-5’s main improvements in one paragraph: It’s cheap, fast at times, and available to all (most people think GPT-4o is state-of-the-art!); it’s better across benchmarks, dominating the price-performance Pareto frontier (some think the upgrade is underwhelming, though, especially compared to Anthropic’s Claude 4/4.1 models); it simplifies the product offering by internally selecting models for you (at its whim); it has superior tool-use skills which entails better agentic behavior (including research); it’s the best model in the world at coding (that’s key to help OpenAI devs build GPT-6 sooner); it still fails ARC-AGI 2; and still sucks at creative writing.
That’s it. It’s what you get from checking the sources I checked (which is, all of them). However, there’s one more thing that no one emphasized—which is also a win for OpenAI—and this one thing is what I consider the most important improvement GPT-5 brings: a huge reduction in hallucination and deception rates.
Earlier this week, I put out a mildly damning post on GPT-5 to heat up the pre-release days. I titled it “GPT-5: OpenAI’s Flagship Model Faces Great Expectations.” After one long section contextualizing the announcement—GPT-4.5 was a commercial failure but not a technical one; the scaling laws are yielding diminishing returns but not stopping; and OpenAI is not falling behind as revenue and growth soar—I exposed my thesis: AI labs are too focused on raising the ceiling of capabilities (e.g., superhuman smarts, PhD-level knowledge, agentic behavior) and too little focused on raising the floor of capabilities (e.g., please, don’t fail this puzzle for kids; please, don’t lie to me; please, don’t invent information and then bury the cues until I’ve lost hours of work; and please, pretty please—don’t glaze every question I ask as the best question ever asked since the dawn of humanity).
I argued AI labs do this because 1) they expect that raising the ceiling will raise the floor, and 2) they don’t know how to do it themselves. AI is too weird, I wrote, and that makes it hard to fill the seemingly easy-to-fill gaps. More importantly, I argued that many users are indifferent to gains from model-to-model updates because they only care about the floor rising. In one sentence: no one gives a fuck how smart AI is if it’s constantly making up stuff. And I pledged: I’d pay twice the price to get the hallucination rate to zero. Well, friends, somehow, OpenAI has delivered.
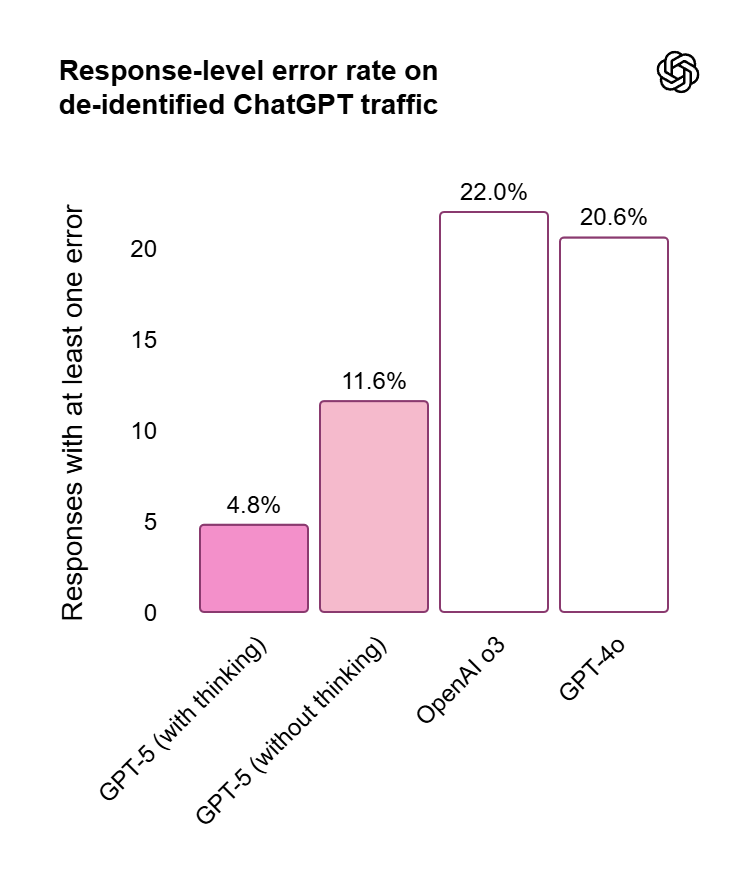
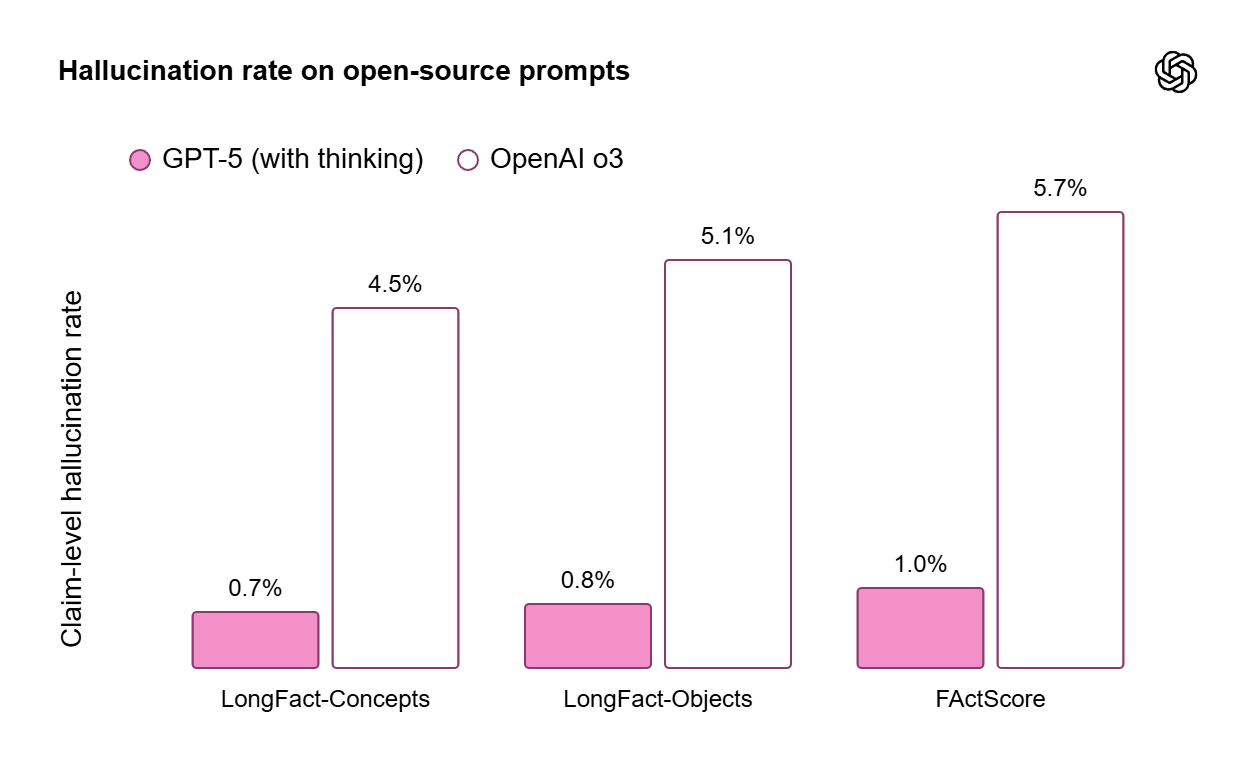
Hallucinations are not at 0% just yet—and they may never get there—but you’ll be glad to learn that the rate at which GPT-5 hallucinates is 44% smaller than GPT-4o (11.6% vs 20.6%) and 78% smaller than o3 when thinking (4.8% vs 22%) for typical chats (the rate is even smaller for “complex, open-ended, fact-seeking prompts,” like those in LongFact and FActScore evals, below 1% in some cases). Here are the graphs (they’re in the blog post but the information is more complete in the system card):
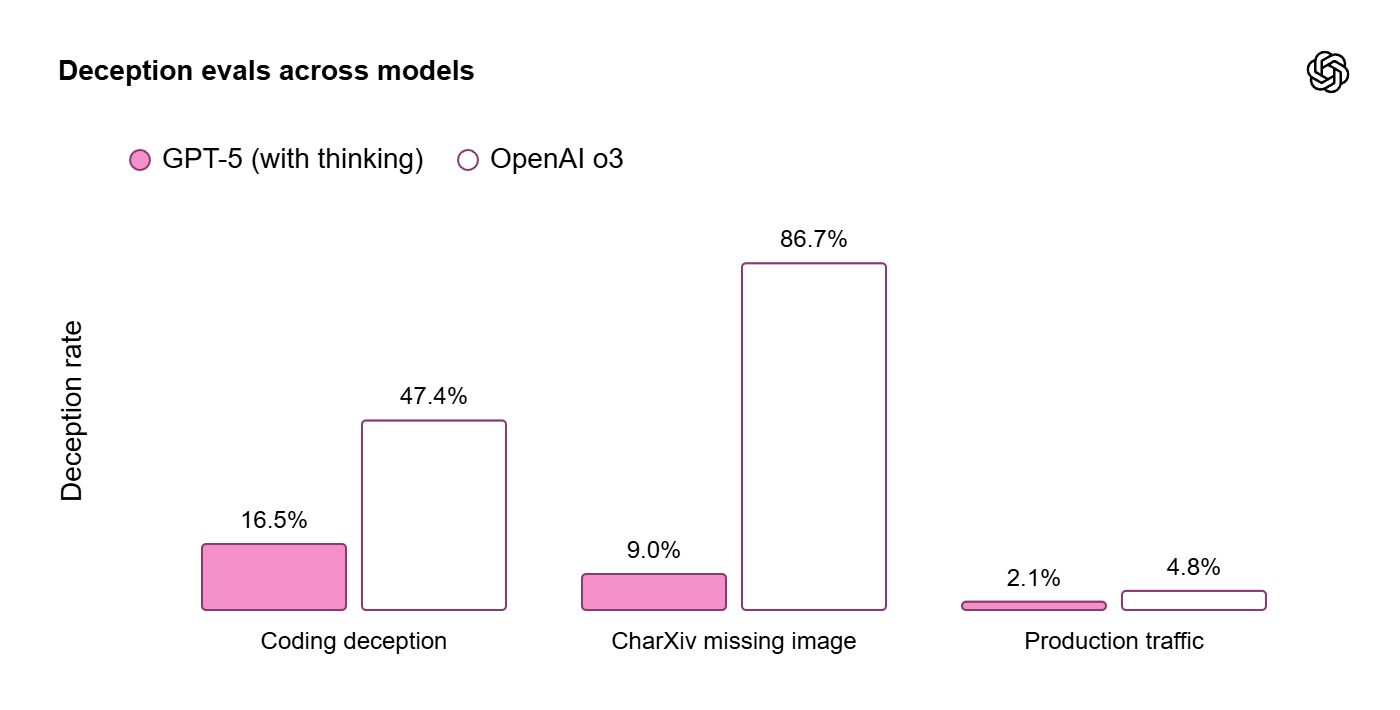
Same thing for the deception rates (e.g., saying it can do something it can’t): In standard ChatGPT conversations, it has gone down from 4.8% (o3) to 2.1% (GPT-5):
I find it fascinating that the one release I consider a victory (insofar as these results are faithfully reflected in the daily use of 700 million people), the AI community thinks is disappointing. My entire Twitter feed is calling out mistakes in the graphs (can happen to anyone, but come on: during the most important product release of the year!), and extending their AGI timelines (I guess they really, really believed we were getting AGI next year or something).
My overall reading is short and sweet (I may have more to report once I’ve tested it in depth, but I don’t think so; in any case I may do an “implications” post, which I know you love): Raising the floor of AI capabilities—less making stuff up and fewer lies—is always a good thing. Also, I’m happy it does suck at writing (said the writer). I’m happy that I got it right when I wrote two days ago that it would be received with “unfair disappointment.” And, finally, I’m happy that people are starting to realize AGI won’t be that easy a target to achieve. With that, make sure to try it and see for yourself; you should have it available in your ChatGPT app. Over and out!
It might "suck at creative writing" from most fingertips ... but I just encountered a short story co-written by a Twin Cities artist and his "Molly" (his AI collaborator) that was truly poetic and surprising, top to bottom. That was an eye-opening first for me. In the right creative hands, we might have a new literary art form.
I’m really glad they’re focusing on lessening hallucinations and not trying to bury the fact they exist (as others corps are doing…)
Really good to see they’re still tracking this metric. Hope that continues