
Inside the AI Industry's Most Expensive Mistake
The absurdity of thinking in tokens


Hey there, I’m Alberto!👋
Each week, I publish long-form AI analysis covering culture, philosophy, and business for The Algorithmic Bridge. Paid subscribers also get Monday how-to guides and Friday news commentary. I publish occasional extra articles and essays. If you’d like to become a paid subscriber, here’s a button for that:
Today, I bring you a hot analysis + hot news, the best mix.

I.
Meta employees have an internal leaderboard called “Claudeonomics.” The ranks go up from casual user to “Session Immortal” to the top tier: “Token Legend.” Setting aside the cringe, it’s crazy that over a 30-day period, total usage on the dashboard topped ~60 trillion tokens (words). For context, it has been estimated that all books published throughout history amount to ~20 trillion tokens.

It’s not just Meta, though. Nvidia CEO Jensen Huang said in the All-In Podcast that if a $500k engineer spent less than $250k a year in tokens, he’d be “deeply alarmed.” When asked whether Nvidia is spending $2 billion on tokens for its engineering team, he said: “We’re trying to.” Last year, OpenAI introduced “Tokens of Appreciation,” a program to recognize developers and organizations that have processed high volumes of data through the API in three tiers: silver, black, and blue.
Token usage is, by all accounts, a new status symbol. Engineers at the top labs boast about token numbers like a bad coder would about lines of code: look how excessive I am. They are “tokenmaxxing,” as the New York Times wrote last month. “An engineer at OpenAI processed 210 billion ‘tokens,’” writes the NYT, “enough text to fill Wikipedia 33 times.”
Some engineers spend more on tokens than they earn in salary. Token budgets are being pitched as a “fourth component” of compensation, alongside salary, equity, and bonuses. Candidates are asking in interviews: how many tokens come with the job? API expenses are now competing with labor budgets.
If you are not burning through your token cap, said Huang, you are like the chip designer who refuses to use CAD tools and instead designs by hand, with a pencil. From an industrial perspective, this behavior makes sense: these are the tools we have. The more you spend, the more they think, and, presumably, the better the output you get, and thus the more benefit you create for your company.
In the “intelligence age,” the token is the unit of cognitive labor.
The obvious reaction is to summon Goodhart’s law or bring up “On the folly of rewarding A, while hoping for B.” Some ask, dumbfounded: What do you think your employees will do if you take this simple, hackable metric as proof of work? Well, hack it. Duh. And so you have guys instructing their bots to run loops with the sole goal to burn tokens or to “be as token inefficient as possible.”
This was my first reaction, too. But then I had a deeper reaction, which is what I want to explore in this post: Why are we stuck with an architecture that forces AI models to “think” in tokens?
Imagine if humans did that.
II.
The idea that “the more tokens you use, the more value you provide” gets backward not only the economic incentives, but also the relationship between thinking and language. I notice it in myself: I rarely think in words. Sometimes, in images. But the vast majority of the time, I think in sensations.
When I’m working through a problem or an essay or an argument in my head, my brain doesn’t produce words. It produces what I can only describe as “attraction points.” As I move through my thoughts, I feel the pull here and there, as if the conceptual landscape that surrounds whatever I’m thinking about has a topology—mountains and valleys and plateaus and, sometimes, marshes—and my mind navigates it by moving from attractor point to attractor point and, at times, away from them, but always with those “sensations” as the vehicle. You could say that my brain knows where the relevant ideas rest geographically.
Insofar as I utter anything resembling a word, it’s more like “aha” or “of course” or “huh?” or “yes, that thing.” And I won’t ever bother explaining to myself what that thing is with all the words I’d need if I were to explain it to someone else, which might amount to one or two hundred, or maybe five thousand, depending on the topic. To me, that thing is simply a hill over there, instantly legible, like a pointer to a more complex idea that I don’t need to parse into language.
Sometimes, that thing is a whole world. And those times, as soon as I mutter “yes, that thing,” my mind is immediately connected to that world and the entirety of its content.
That’s the power of thinking in sensations.
If I were asked to use an analogy, I’d say that thinking with words is like moving from point A to point B, whereas thinking in sensations is akin to teleporting from point A to point B. You should try it. (That is, by the way, my best take on what I believe “thinking in latent space” must feel like for AI models; sensations rather than words. What is it like to be a pre-trained model, right?)
The whole thing happens pre-linguistically, much faster than it would take me to put it into words. Only later, I decide whether I want to polish it with the structural superiority of language. I might need it to “export the result,” to tell someone, to write it down, to check whether the details of my map match the territory, etc. For that, I need the words. But words are a lossy compression of something richer. More concrete but less precise; more transferable but less detailed. (An image is worth a thousand words; well, a sensation-level thought is worth a novel.)
Before you are inclined to disagree with me on this—language is how we think and how we understand the world and nothing of importance happens pre-linguistically or supra-linguistically, and that if humans are special compared to animals, the reason is language, etc.—let me share some research that I bring up in connection with an exchange between Elon Musk and Yann LeCun.
In 1945, the mathematician Jacques Hadamard surveyed the greatest scientific minds of his generation—Polya, Wiener, Lévi-Strauss, Einstein—about how they actually think. Almost none of them said words. Einstein’s response is the most famous: “The words of the language, as they are written or spoken, do not seem to play any role in my mechanism of thought.” The elements of his thinking were, he said, “of visual and some of muscular type.” Conventional words had to be “sought for laboriously only in a secondary stage.” He told Max Wertheimer the same thing in 1916: “I very rarely think in words at all. A thought comes, and I may try to express it in words afterwards.”
Don’t mistake my enthusiasm for an attempt at comparison, but this is exactly how I think.
Eighty years later, in 2024, Evelina Fedorenko’s lab at MIT confirmed this with neuroimaging: the brain’s language network—left frontal and temporal cortex—doesn’t activate during reasoning tasks, including logic, spatial processing, and programming. Language and thought use different hardware. Fedorenko’s paper in Nature that same year goes further, arguing that “language is primarily a tool for communication rather than thought.” It “only reflects, rather than gives rise to, the signature sophistication of human cognition.”
We don’t parse the world with words. The brain reasons in one system and translates into language through another. That’s exactly what happens to me, what Einstein’s genius was made of, and what current AI models don’t do.
III.
But they could.
AI models have the infrastructure to process information at a pre-linguistic level as well, in the “latent space.” It’s the AI labs who force them, through the process of post-training, to move through a taxing mire of sequential symbol generation when they apply inference-time techniques, which is to say, they force them to “think before you respond.” It’s like being forced to narrate every thought aloud before you’re allowed to have the next one.
The AI labs do that because pre-trained models are not that good—when an AI model responds instantly, it’s quite dumb—and, unfortunately, they’ve found no other way to let models think through their answers at scale.
How come AI models are either too imbred to think (pre-trained models) or too rigid to think wordlessly (post-trained models)? We assumed OpenAI’s o1 was the next holy grail of scaling—a “new paradigm,” some naive voices called it—but the presumed fix was actually a crutch.
The real solution would be to build an AI system that had the intelligence and “reflection” skills of post-trained models, combined with the representational richness of the latent space; alas, we have to choose between both: between a dumb wordcel or a mute savant.
You may be wondering why this “inference-time thinking” matters at all. Well, it matters because AI models that generate vast quantities of tokens at inference time with the sole goal of “thinking”—that is, improving benchmark scores—are the sole reason why companies like Meta are reaching two-digit trillion token spend on Claude. Thinking in tokens is, thus, not the celebrated breakthrough they made it to be last year.
It is, actually, a prosthesis, a scaffolding apparatus that the AI labs used to erect a taller building and then, when they realized the building would immediately collapse if they removed it—going back to pre-training is not an option—they started to convince us—and themselves—that the scaffolding was actually load-bearing architectural elements: the bricks and columns and arches and vaults of this cathedral they are erecting for the machine god.
And I wonder: instead of resorting to this ugly scaffolding apparatus, wouldn’t they be better off in the long run if they accepted that the majority of this ridiculously large amount of tokens is wasted? Wouldn’t they be better off if they rethought the entire cathedral from the ground up in a way that ensured that, once they removed the scaffolding, it would stand on its own? Maybe they should do that instead of patting themselves on the back, as they do with their tokenmaxxing dynamics, for participating in this folly.
I’m not stupid, though. I know they don’t do this because when it comes to the most transcendent technology of our era—I say more, the most transcendent technology in human history—making a clean profit is what truly matters. It’s just not economically feasible to overhaul an entire industry just because it’s resting on top of a fallacy. Won’t somebody please think of the shareholders?
So, no, I won’t get between you guys and your Token Legend status.
IV.
But not everyone is thinking in economic terms.
There are some—not many—willing to think, for some reason that eludes my analysis, in scientific terms. They’ve done so for much longer than I have been aware of their efforts. Having been denied the popularity they deserve, they have worked in secret, without much publicity, on the fringes of the industry, sometimes never leaving academia, sometimes regretting having done so.
While the labs kept amassing funding and building datacenters, these outcasts were trying to undo the absurdity of forcing AI models to think in tokens. “We will never achieve true machine intelligence if we keep using tokens to encode thought,” they say. “It makes no sense that an AI model has to spell out what it ‘knows’ in order to know it,” they say.
But no one ever listens.
In short, they want to prove that the AI labs worship a god that has no clothes. The question they ask is not “how do we generate more tokens with less compute?” Which is a reasonable question about scale and efficiency, but “how do we stop needing so many tokens for tasks that require reasoning?” That’s also a question of efficient scale, but more so of architecture. They don’t ask: how do I efficiently scale all these grains of sand to build my cathedral? Or: How do I pretend that this scaffolding belongs to the cathedral? No, they make sure to invent the brick and the column and the arch and the vault.
One such person is Yann LeCun.
LeCun is the former chief AI scientist at Meta—which means, by the way, that the most prominent research avenues that explore this question from a scientific lens have been housed, ironically, at the very company whose employees are playing pretend with their token-wasting gimmicks.
Indeed, Meta’s FAIR lab—Yann LeCun’s group—published “Coconut” (Chain of Continuous Thought) in late 2024, a model that reasons through continuous space instead of decoding into tokens. The same lab released the “Large Concept Model,” which replaces next-token prediction with next-concept prediction at the sentence level.
And then there is JEPA, LeCun’s life project. JEPA, or Joint Embedding Predictive Architecture, doesn’t predict tokens or pixels but meaning; abstract representations in latent space. I-JEPA does it for images. V-JEPA does it for video. VL-JEPA for vision and language, and so on. LeWorldModel, published in March, is the first end-to-end JEPA trained from raw pixels. The premise across: if you want a system that understands the world, stop forcing it to narrate.
Naturally, having used JEPA to predict the caricature that Meta would become with the precision that only a sensation-level thinker can achieve, LeCun left in late 2025.
The proximate cause was organizational. Zuckerberg hired Alexandr Wang, the young founder of Scale, to lead a new Superintelligence Labs. And LeCun—Turing Award winner, twelve years at the company—was told to report to him. But the real cause was, again, architectural.
LeCun has been calling LLMs “a dead end” for years, but Meta went all in in a sort of FOMO-fueled fickleness that’s idiosyncratic of Mark Zuckerberg. Then Llama 4 flopped. Zuck, furious, sidelined the research org and doubled down on what LeCun calls “safe and proven” approaches. Then he announced Hyperion, a datacenter the size of Manhattan. And then, after LeCun launched AMI labs to pursue his vision, Meta’s latest model, Avocado, was delayed due to performance concerns (translated: it sucked).
To me, Meta has been out of the race for a while, but this delay, together with the constant restructuring and LeCun’s departure, was the definitive sign.
V.
Things just got interesting.
As I was finishing this piece, Meta launched Muse Spark, its newest model—the first in quite some time—and one that appears to rival the best on the market. Muse Spark is not bad on paper, with decent scores, but my reading is that it’s essentially a “panic release” due to the much superior quality of Claude Mythos (unreleased), given that it’s not SOTA on agentic evals (the ones that matter). Meta wanted to be in the conversation.
But then something clicked when I saw this chart by Stripe CEO, Patrick Collison:
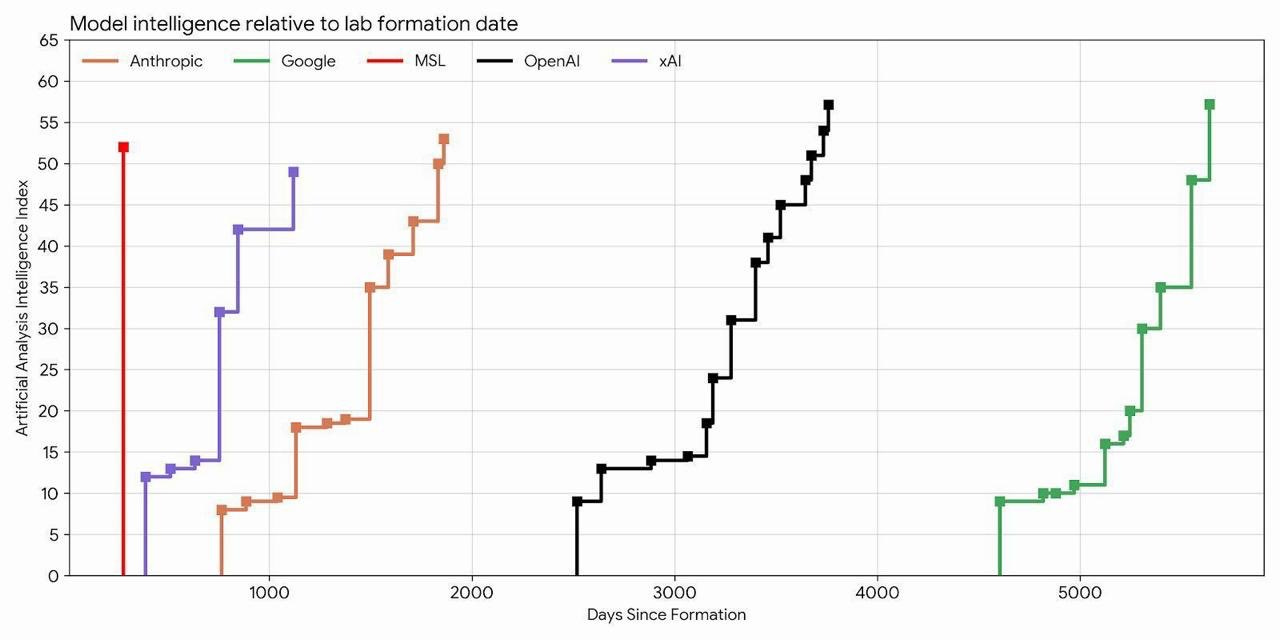
(Edit: people are correctly pointing out in X the chart crime above. The criteria for the data points differ between orgs; Meta’s AI efforts were not born with MSL so why is it just a straight line? But the point it tries to make—which is the opposite as mine, to be clear—is still there in a chart that takes into account Meta's history. I found a more correct chart in the comments of Collision’s post:
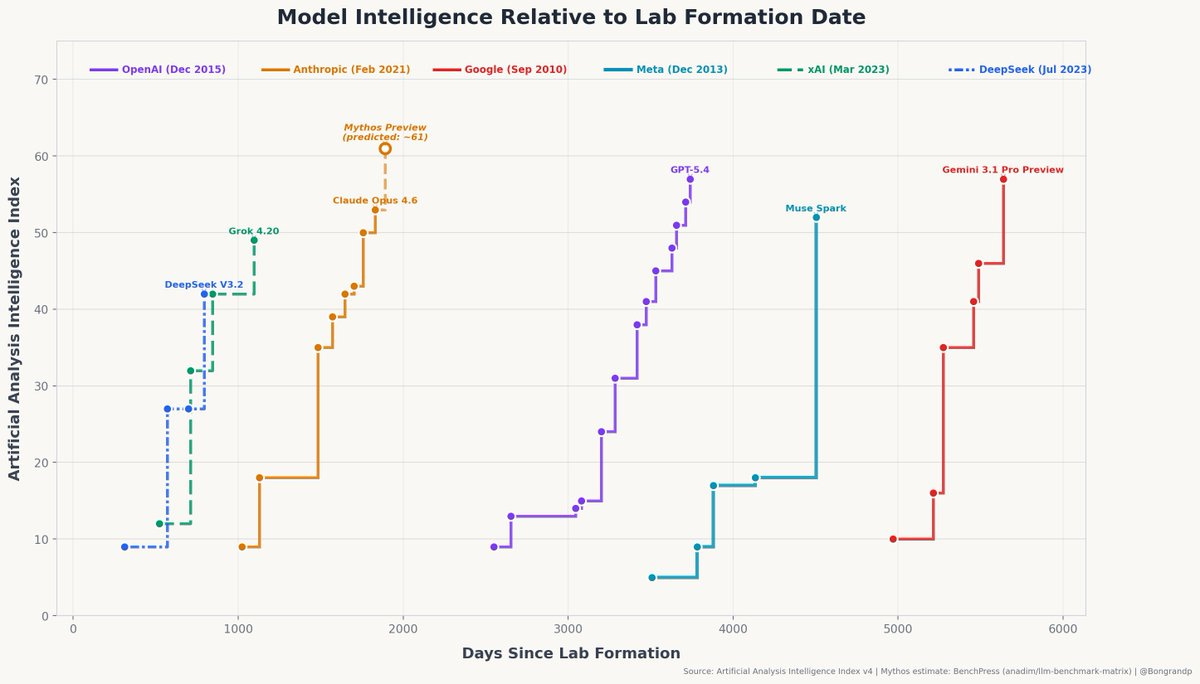
That straight line that ends with Muse Spark, combined with the delay of Avocado and the flop of Llama 4 is what backs my hypothesis below, which, to be fair, might still be wrong; we may never know.)
How the hell did Meta achieve this milestone?
I don’t trust the numbers at all because we’ve seen benchmark gaming way too often, but still, it’s quite impressive that they got so high overnight.
And then, as I was thinking of a way to circle back to the beginning to finish the article, I read that word again: Claudeonomics.
Wait…
Did Meta just spend 60 trillion tokens last month on Anthropic models to distill from Claude’s reasoning traces the data they needed to bootstrap this new release?
If that’s true, that’s pretty intense.
Here’s how they could´ve achieved it: Meta spins up a bunch of accounts (not fake, as were those from the Chinese labs) and then uses those accounts to bombard a stronger model (Claude) with carefully crafted prompts designed to extract its reasoning patterns. Then they collect the outputs. Then you use those outputs as training data for their own model. The “student” learns to mimic the “teacher’s” behavior without having to figure it out from scratch. It’s dramatically cheaper and faster than developing capabilities independently.
Am I accusing Meta of doing something illegal? I don’t think so.
Anthropic’s ToS prohibit using outputs to train competing models, but enforcement against Meta—a massive legitimate customer—is a very different proposition than catching proxy networks from China.
I say more: Muse Spark training needs are probably the main reason why Anthropic’s run rate revenue is at $30 billion right now, right on time for a very successful IPO. They are more than happy to have Meta “breach” their ToS!
But even if illegality is off the table, if this is true, it’s a stain on Meta’s efforts to catch up with the top labs. Whereas Anthropic and OpenAI have been working hard to achieve a much better pre-trained model onto which to build the next generation of agents, Meta is out there, with more compute than it can use, struggling to milk Claude, only to fail to beat it on the most important benchmarks.
I guess the Meta guys didn’t like this article at all because they just shut down Claudeonomics.
The thesis I had in mind—that it’s time for AI models to stop thinking with words—needs to be updated. If my suspicions are correct, the true thesis is this: It might be a waste of compute that current AI models generate so many tokens when they think, but if they didn’t—if they could think with sensations rather than words—then Meta couldn’t have trained Muse Spark.
Sometimes, overthinking is all you need.
There are many posts about Claudeonomics and, of course, also about Muse Spark, but I think you are the first one to draw a (distillation) line. Wild!
Beyond this, your reflections on tokenmaxxing - and the natural human shortcut instinct - teach a lesson about valid metrics of AI usage, in the AI labs and in other industries.
"More of the same" rarely leads to quality leaps; the abundance of AI-generated output should rather trigger a "less is smarter" incentivization.
So much of this is so worthwhile! I wish I had a superduper amplifier. What most needs to be heard far and near is: "It might be a waste of compute that current AI models generate so many tokens when they think." Huang setting tokens as an ultimate goal? Doesn't sound right. It's in the category of "If all you have is a hammer...." Thanks for this piece of writing!