
Harvard and MIT Study: AI Models Are Not Ready to Make Scientific Discoveries
AI can predict the sun will rise again tomorrow, but it can’t tell you why

A study by researchers at Harvard and MIT sheds light on one of the key questions about large language models (LLMs) and their potential as a path to artificial general intelligence (AGI): Can foundation AI models encode world models, or are they just good at predicting the next token in a sequence?
(This dichotomy between explanation and prediction is a fundamental scientific conundrum that goes beyond AI—more on that later.)
The authors trained a transformer-based AI model to make predictions of orbital mechanics (think: Kepler’s discoveries of how planets move around the sun) and then wanted to test whether it had learned the underlying Newtonian mechanics (the laws of gravitation). They hypothesize that if the AI model makes correct predictions but doesn’t encode Newton’s laws, then it lacks a comprehensive world model.
This would be powerful evidence against the idea that AI models (as they are today) can understand the world, which would be a big setback to the AGI dream.
They chose orbital mechanics because it’s historically accurate: Newton built on Kepler’s discoveries to derive his famous force laws. Kepler predicted the “what”—planets follow elliptical trajectories around the sun—but he never found a satisfying “why” (he invoked the divine harmony, but for some reason it didn’t quite work). Newton formalized Kepler’s observation by discovering the causal mechanism of planets’ movements: the force of gravity.
Critically, Newton realized this mechanistic explanation applied to many other things besides planets, like an apple falling from a tree.
That’s the power of a world model. It allows you to go beyond the immediately observed phenomena and extrapolate the underlying cause to unobserved and seemingly unrelated scenarios. Humans do this all the time, since we are toddlers. If you see someone pour juice into a cup and then knock the cup over, you understand, even without seeing the spill, that the juice will be on the floor. You don’t need to witness the outcome more than once to know it. That’s because you’ve internalized the world model: “liquid in cup + tipping = spill.” Once you grasp that, you can predict all sorts of situations that you have never encountered.
This broken link between prediction and explanation has been a shortcoming of modern AI models for as long as neural networks have dominated the field (as early as the 90s, and even before). It became obvious when large language models (LLMs) grew in size and power over the past decade, now capable of solving PhD-level science problems, yet strangely unable to figure out easy ones like those of ARC-AGI 2. Why? Because they require encoding a world model beyond observed data.
Another good example is self-driving cars. Why can Waymo robotaxis navigate the Bay Area and other US cities with ease, but deploying a fleet in every major city worldwide—and solving traffic jams at once—is still unfeasible? Because self-driving software lacks a true world model of “how driving works,” the kind needed for one-shot generalization.
This team at Harvard and MIT set out to investigate whether this is a fundamental limitation of AI models, and if large language models can eventually overcome it on their own, or if a deeper breakthrough will be needed. So let’s see what they did, what they found, what the limitations of their approach are, and the kind of future work that could reveal more.
Let’s start with a description of “world model” vs. “foundation model” (that’s how the authors refer to transformer-based AI models, which include virtually every AI product or tool the average person has ever used). This difference is the basis of the study.
(I will make several digressions as standalone paragraphs in parentheses. I encourage you to read the entire thing, but it’s safe to jump over them if you only want the gist. Here’s the first one: I have an objection to the authors’ use of “foundation model.” This concept is supposed to apply to large models trained on tons of data and can be applied to a range of use cases, not any transformer-based AI model. However, the authors refer throughout the paper to a 109-million-parameter transformer model as a “foundation model” (the main experiments are done on this small model, but they also test well-known LLMs). 109 million parameters is ~4 orders of magnitude smaller than the largest language models available today, which are ~1-2 trillion parameters. This may seem like a semantics issue, but previous research has offered evidence that scale leads to capability emergence—perhaps a 100M AI model fails this task, but a 1T AI model doesn’t. I make this clarification so you don’t confuse the authors’ use of “foundation model” with “any LLM as large as it might be.” But I’m not here to defend the (often contested) research on emergent capabilities, so I will refrain from using this nomenclature and will resort to the more general “AI model” and will specify as “transformer” or “LLM” when the distinction matters.)
The authors write:
A foundation model uses datasets to output predictions given inputs, whereas a world model describes state structure implicit in that data.
Understanding this is fundamental to interpreting the results. I started this article with the Kepler-Newton story because it’s a good example of the contrast between a token-predicting model and a world model (kudos to the authors for using such an appropriate analogy). I already explained what Kepler and Newton did, but let’s see how their approaches map to the foundation vs. world model distinction.
Kepler inferred the movement of the planets from data on past trajectories (inputs) to predict future trajectories (outputs) using geometric methods. Newton took those empirical patterns and showed they were consequences of deeper principles: universal gravitation and the laws of motion. He introduced a unified framework that connected falling apples to orbiting moons, invented calculus to describe continuous change, and gave us an explanatory world model—the ”state structure implicit in that data”—of physical reality. It was Newton, not Kepler, who uncovered the underlying dynamics between forces, masses, acceleration, and motion, which made sense of the data.
This is why AI scientists can’t shut up about world models and why they’re obsessed with the fact that LLMs may not be able to do by themselves what Newton did. To make scientific discoveries beyond superficial observations, you need a world model.
(Many of you are probably familiar with Einsteinian relativity, so I will preemptively address your concerns here: Yes, Newton’s gravitation laws are imperfect; they don’t work as you get closer to the speed of light. Does this mean they lack explanatory power? The answer is no. Scientific models are valid within the assumptions they’re built on; Newtonian physics came from observing the planets, but applies to everything as long as the assumption of low speeds remains. Newton’s framework is incomplete, but unlike Kepler’s, it is explanatory. Einstein’s relativity is explanatory as well and more complete, but, as science goes, also imperfect; it fails at tiny scales. No physics framework is complete; physicists are still looking for a way to combine gravity and the other fundamental forces—electromagnetism and the strong and weak nuclear forces—well-described by quantum mechanics.)
Empirical data taken from the world has hidden structure—orbital mechanics does, and also language—and so the premise of the LLMs at the core of ChatGPT, Claude, Gemini, Grok, DeepSeek, etc. is that they can encode that structure (syntax, semantics, etc.) just by reading tons of data many, many times and being trained on predicting the next token. And indeed they do—they write well and have a deep grasp of the form of language, and only in edge cases can you see the trick being played.
That’s what the authors want to discover: Can AI models leap from making predictions to “developing reliable world models”? But instead of testing with language, which is fairly complex and hard to analyze, they focused on classical physics.
(The implementation details are a bit technical, so I skipped them; the paper is rather short in case you want to read about inductive bias and inductive bias probes. To give you an overview: the authors argue that you can check whether an AI model has “recovered” the correct world model by checking its inductive bias, which is a scientific way to say “guessing style.” Another method that would work is mechanistic interpretability, which is a “let’s cut this AI open and see what’s inside” kind of method. I’d love to see Anthropic’s interpretability team build on this study using Claude Sonnet 4, which the authors use, but further fine-tuned on orbital data. I’m curious because although this study will tell us whether AI models can encode world models, in case the answer is negative, it wouldn’t be able to unveil exactly how they make good predictions from poor world models at all; you need mechanistic interpretability for that.)
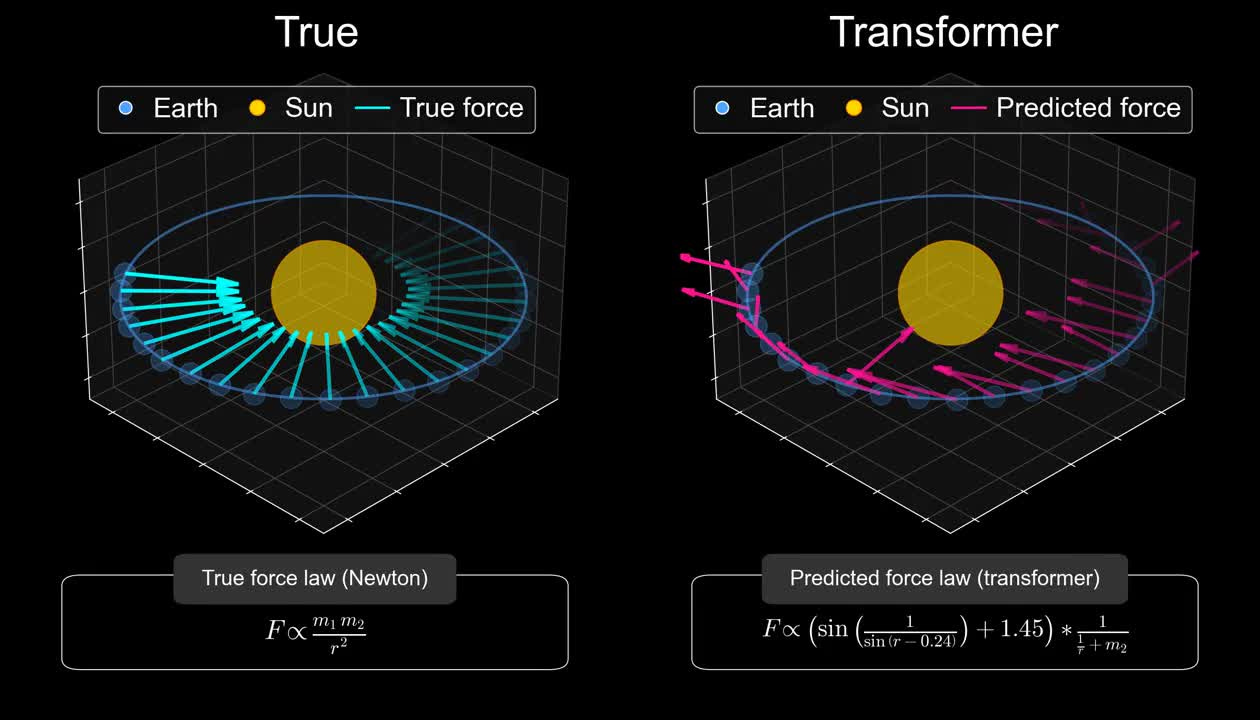
The authors trained a small transformer on orbital trajectory data (specifically, sequences of coordinates from 10 million simulated solar systems, totaling 20 billion tokens). They wanted to see whether the model would use Newton’s laws to predict the force vectors driving the motion, or whether it would simply make up its predictions without grasping the actual physics.
They concluded that AI models make accurate predictions but fail to encode the world model of Newton’s laws and instead resort to case-specific heuristics that don’t generalize.
Here’s a visual showing the true and predicted force vectors acting on our beloved planet Earth. Clearly, something’s off with the AI model.
Here’s the rest of the solar system; the same pattern.

However, here are the predicted (solid line) and true (dotted line) planet trajectories.
What’s going on? The trajectories are nearly perfect, but the predicted forces are all over the place.
Whatever it is that the AI model has used to make accurate predictions has no resemblance whatsoever to the actual laws of gravity. Indeed, if you look at the bottom part of the first gif, you will see two different force laws, Newton’s on the left and a nonsensical law on the right. The authors discovered that the predictions don’t generalize to solar systems the AI model has not seen.
When testing for solar systems across different galaxies (distinct samples), the authors also discovered that the AI model encodes different force laws, so it isn’t even coherent in its incoherence with our universe.
This is huge.
If AI models fail to recover Newton’s laws but keep the same wrong law across samples, it would imply they encode a world model that’s, for some reason, different from the one governing our universe, which is already bad. But the fact that the wrong laws vary depending on the samples they’ve been trained on reveals that AI models are simply unable to encode a robust set of laws to govern their predictions—they’re not merely bad at recovering world models but inherently ill-equipped to do it at all.
They use disposable rules of thumb to make calculations about planetary trajectories, nailing those that fall within the case boundaries they’ve seen but missing anything that doesn’t resemble what they know. This is strong evidence in favor of one of the most common arguments against LLMs: they only generalize insofar as they are familiar with the thing or the shape of the thing they are asked to generalize to, but no more than that.
The authors also tested state-of-the-art LLMs like OpenAI’s o3, Anthropic’s Claude Sonnet 4, and Google DeepMind’s Gemini 2.5 Pro (they didn’t fine-tune them on orbital data and instead used the context window to include the relevant information). Here’s what they found.

The graphs are not as beautiful or visually revealing, but equally damning: The LLMs make accurate predictions for the trajectories but then make up strange force laws that have little to do with Newton’s laws, despite having seen Newton’s laws many, many times in their training corpus.
So, why does this happen? Why are AI models, small and large, making extremely accurate predictions from poor world models that don’t resemble the actual world model they should be using?
The authors tested two other applications—lattice problems and the Othello game—to address this question and see whether the problem emerges in different contexts. I won’t go over the details because the results point in the same direction: “models group together distinct states that have similar allowed next-tokens.” This means that the “next token” policy overrides the human tendency to develop a world model. (But perhaps the reason is worse; perhaps a deep learning AI model is architecturally incapable of developing correct world models.) We may have to wait for mechanistic interpretability to give a definitive answer to this question.
My guess is that training an AI model to be optimized for a target in the form of “what’s the most probable next token?” provides the model with incredible capabilities, but among them, the very toolkit to bypass the need for encoding a robust world model that would otherwise allow it to generalize its predictions.
Humans are unable to acquire more than an infinitesimal fraction of the amount of data LLMs see during training, so we have evolved to make the most out of that scarce data. Chess grandmasters, for instance, can’t play millions of games, so they have to use reasoning, intuition, creativity, and high-level structures between chess pieces to come up with good moves. The same goes for toddlers watching a glass spill juice on the ground and experienced drivers being adept anywhere in the world.
Human brains are predictive machines, but not only predictive machines.
Here’s a more sci-fi reflection: If we could build an AI model that could gather all the data in the universe, then there would be no need for a world model, because no data would be “out-of-distribution.” But that’s not what happens in practice: we will never not be short on data. To generalize from experience, one needs to encode a set of functions that describe not just what will happen but why the world works that way. AI models fail to do that. Humans are far from perfect, but much better. That’s the conclusion of this study. (More research on this would be extremely welcome!)
The implications for the immediate future of AI are huge. I know this post is already quite long but I want to take the opportunity to go a bit in-depth into that question: What does this mean for LLMs, is this a victory for the critics of LLMs, and what is the fate of scientific inquiry in the broader sense if some of our most powerful tools are limited by their lack of explanatory power?
The first thing I will say right away is that this is not a defeat of LLMs.
I’ll be charitable toward LLMs despite these results (and similar findings in other studies like the now-infamous “The Illusion of Thinking” by Apple researchers). LLMs might be bad at generalizing, but humans are sometimes too good—don’t make the mistake of over-extrapolating these findings. A lack of a world model doesn't equate to uselessness. There are plenty of practical use cases where LLMs prove helpful (whether the training and inference costs are justified is another question, and one I’m still unsure about).
But hear me out—even for the bigger quest of “automating scientific discovery,” LLMs are probably not dead weight. Not even the strongest LLM critics like Gary Marcus or Yann LeCun would take such an extreme position. The correct conclusion from this study is that LLMs, at least as they are now, are insufficient. That’s it.
So, what’s the correct course of action now?
AI companies could keep making them bigger in the hopes they eventually learn to encode Newton’s laws of physics from orbital trajectory data or whatever, but I don’t think that’s the right approach. To quote another of LLMs’ harshest critics, Grady Booch, responding (in a now deleted tweet) to Sam Altman about the $7 trillion he said he’d need to “reshape the global semiconductor industry”:
If you need $7 trillion to build the chips and the energy demand equivalent of the consumption of the United Kingdom, then—with a high level of confidence—I can assure you that you have the wrong architecture [emphasis mine].
So, contrary to making me more bullish on “just scale,” this study updates me in favor of a complementary approach (scale is still fundamental, don’t get me wrong).
If you’re a regular reader of this blog, you know this has been my stance for a while, pretty similar—or rather, influenced by—François Chollet’s view: the AI community has over-focused on increasing crystallized intelligence (which is knowledge and static skill) rather than fluid intelligence. As Chollet says, they confuse intelligence with “having the skill to solve a problem.” A better framing, he argues, is intelligence as the meta-skill of efficiently using previous experience to adapt on-the-fly to solve new problems (thus acquiring new skills). That’s what humans do.
(If you want an in-depth resource on this, you should watch Chollet’s recent half-hour talk at Y Combinator; one of the best expositions I’ve watched lately on AI and refreshingly contrarian to the typical narratives.)
If Chollet is right—which, admittedly, is far from proven—it means that, until AI systems learn to combine basic knowledge-having and static skills with what he calls formally “discrete program search,” they will have no chance to be truly intelligent in the human sense. We humans have a good intuition of where to go to solve a problem from just a few examples; we make “fast-but-maybe-wrong judgment calls.” LLMs are super good at making judgment calls, but have no means to narrow down the space of reasonable solutions. So, instead of coming up with Newton’s laws of gravitation, they come up with a different—and rather strange—law for every sample.
Chollet is working on solving this in his new company, Ndea, as is Yann LeCun at Meta with his JEPA framework. Just three months ago, right at the beginning of his talk at Nvidia GTC 2025, LeCun said: “I’m not so interested in LLMs anymore. . . they’re in the hands of product people, improving at the margin.” LeCun is explicitly concerned about LLMs’ inability to encode world models.
I don’t know what the exact component is missing for LLMs—otherwise, I’d be a billionaire by now—but the ability to encode world models is part of it. I may not have a formalized version of the laws of gravity in my brain, but, as a human, I know that if I’m lying down under an apple tree, I may get a treat right on my forehead—even if, unlike Newton, I’ve literally never seen an apple fall from an apple tree.
Before jumping into the final part of this article (I promise we’re close to the end!), where I will get a bit philosophical, I want to share here an interesting question Dwarkesh Patel has been asking his pro-LLM podcast guests for many months, never receiving a satisfactory answer. Paraphrasing:
If AI models have read the entire internet, how come they are yet to make a single fundamental scientific discovery?
Well, this study is why: AI models are not ready to make scientific discoveries.
Setting aside LLMs, even non-LLM deep learning AI systems like DeepMind’s AlphaFold, who are fully dedicated to scientific tasks, are not making novel scientific discoveries but “merely” (not derogatory, this is super useful) predicting patterns from existing data; does AlphaFold understand the mechanisms that underlie the folding of proteins or is it just really, really good at predicting the folding structure from amino acid sequences without attending to the casual biophysical mechanisms behind the process? Or, put it another way: Is AlphaFold more a Kepler-like AI or a Newton-like AI? My guess is the former.
I want to approach this entire discussion between predictive and explanatory science from a more philosophical perspective (there’s actually no other way). For that, I will go back to MIT, to the Brains, Minds, and Machines symposium held during MIT's 150th birthday party in 2011, and listen to Noam Chomsky again—maybe he was wrong about language, but I believe he was right in the broader sense. He said:
Statistical models may provide an accurate simulation of some phenomena, but the simulation is done completely the wrong way; people don't decide what the third word of a sentence should be by consulting a probability table keyed on the previous words, rather they map from an internal semantic form to a syntactic tree-structure, which is then linearized into words.
“Statistical models may provide an accurate simulation of some phenomena, but the simulation is done completely the wrong way.” He was talking about language, but notice how well his sentence fits the discovery that AI models are incredibly proficient at making good predictions from poor world models!
Peter Norvig, at Google at the time, responded at length to Chomsky in an essay entitled On Chomsky and the Two Cultures of Statistical Learning (as a quip to C. P. Snow’s The Two Cultures and the Scientific Revolution). His criticisms are harsh and a bit ad hominem at times, but well thought out nonetheless. Here’s what he wrote:
Many phenomena in science are stochastic, and the simplest model of them is a probabilistic model; I believe language is such a phenomenon and therefore that probabilistic models are our best tool for representing facts about language, for algorithmically processing language, and for understanding how humans process language.
I believe LLMs and chatbots like ChatGPT have proven that Norvig was right about language: A probabilistic model is enough to resemble language mastery (including syntax and semantics, not sure about pragmatics because AI models lack the context humans take for granted). They’re also our best tool for “algorithmically processing language.” But, beyond language, they seem not to be enough to encode a model of why the world works in a certain way (notice this was written in 2011, a decade before ChatGPT!, and it’s still wrong despite the huge advancements in AI).
In that broader sense, Chomsky was right. And indeed, he meant his remarks in this broader sense, not just for language. In a passage that Norvig chose to leave out, Chomsky argues that you could even “do physics” (his quotation marks) this way, by doing what he calls “sophisticated statistical analysis” to make predictions. From the transcript:
. . . instead of studying things like balls rolling down frictionless planes, which can't happen in nature, if you took a ton of videotapes of what's happening outside my office window—leaves flying and various things—and you did an extensive analysis of them, you would get some kind of prediction of what's likely to happen next, certainly way better than anybody in the physics department could do.
This is exactly what happened in the study: transformers and LLMs can take millions of data points and make absurdly accurate predictions, yet they will learn nothing about why the planets move that way. Isn’t this incredible? Chomsky is saying this in 2011!
LLMs are so good at predicting the orbital trajectories of made-up planets that the surprising thing is not that they didn’t learn Newton’s laws but that they were able to make such incredibly accurate predictions without them! I’d call that a success, but by no means is it a complete scientific success. Hence, LLMs are insufficient.
That’s what Chomsky is talking about here—the power of predictive analysis lies in knowing what happens next, but it’s in no way useful to knowing why it happens and thus is ungeneralizable to any scenarios with the slightest variation in conditions. There’s a trend in the scientific community, Chomsky lamented, to call that a success, but that’s “novel in the history of science.” Science is not about “approximating unanalyzed data” but about understanding the principles governing that data.
Norvig, not knowing that LLMs would prove him both right and wrong, squarely disagrees. Further down his essay, now in a more philosophical tone, he cites Leo Breiman and his paper on Statistical Modeling: The Two Cultures, which is an intermediate inspiration for Norvig’s essay, also influenced by C. P. Snow’s insights on the cultural wars between science and the humanities, and writes:
Breiman is inviting us to be . . . satisfied with a function that accounts for the observed data well, and generalizes to new, previously unseen data well, but may be expressed in a complex mathematical form that may bear no relation to the "true" function's form (if such a true function even exists). Chomsky takes the opposite approach: he prefers to keep a simple, elegant model, and give up on the idea that the model will represent the data well. Instead, he declares that what he calls performance data—what people actually do—is off limits to linguistics; what really matters is competence —what he imagines that they should do.
It’s funny that Norvig sides with Breiman here, knowing what we now know from the new study. The force laws that LLMs and AI models recovered to make their predictions indeed bear “no relation to the true function’s form.” So… we should just accept it, then? Even if the true function not only exists but is known to us—what an absurd position to take!
He writes that Chomsky prefers to “give up on the idea that the model will represent the data well,” which is, in my opinion, an uncharitable interpretation. What I believe Chomsky meant is that the true function is more important than the accurate predictions, not that the predictions are worthless. Finding Newton’s laws is more important than making correct predictions about future trajectories because that’s how you make sure your predictive skills are generalizable to unseen cases!
That’s how you understand the world—by caring about the “whys”, not just the “whats”.
I will make a confession now.
I don’t think modern scientific efforts, including but not limited to modern AI, are leaning more on the side of “accurately modeling the world” and “making predictions about phenomena” because scientists don’t care about the underlying explanations and the “whys” of the world (even a three-year-old child cares about that stuff). I think the real reason is a bit more forgiving and, perhaps, a lot more pessimistic.
The universe is too complex for us. Scientists have merely made, on behalf of humanity, the difficult decision to put a good face on this terrible possibility.
Having long ago accepted this defeat, Norvig writes:
Why is the moon at the right distance to provide a gentle tide, and exert a stabilizing effect on earth's axis of rotation, thus protecting life here? Why does gravity work the way it does? Why does anything at all exist rather than not exist? . . . why questions can only be addressed by mythmaking, religion or philosophy, not by science.
He seems deeply unbothered by these mysteries. (I urge you to watch this clip where the late physicist Richard Feynman settles the question of how science deals with “why”, taking a similar position to Norvig’s with a bit more nuance.)
However, although the ultimate whys of life and the universe are beyond our grasp (and, seemingly, that of our artificial companions), and will probably forever remain so, the intermediate whys are approachable. That’s where the debate matters. That’s why Chomsky’s position matters. That’s why, in the face of unfathomable mysteries, this study about AI models and LLMs matters.
You can handle hard whys exactly how you’d do when answering your three-year-old kid who’s entered the “why” stage, but with the rigor and formality of science. If you asked me, “Why do planets spin in elliptical orbits around the sun?” I’d respond with: “Because there’s a force acting on them that’s proportional according to a gravitational constant G to their mass and that of the sun, and also inversely proportional to the square of the distance between the centers of planet and sun.”
That’s more than what AI models were able to infer from their perfect predictions of orbital trajectories. And I could do this for the glass that falls and spills the juice, and the driving norms, and whatnot. The intermediate whys matter.
But I will admit a compromise between the two cultures, as well as between the pro-LLM culture and the not-so-pro-LLM culture. Because if you then asked me, “Ok, so why is Newton’s gravitational constant G = 6.6743×10−11 m3⋅kg−1⋅s−2?” I’d have no choice but to shrug quietly and keep drinking my morning coffee, unbothered, like Norvig, by the mysteries that only concern philosophers, myth-makers, and gods.
This is by far one of the most interesting articles I’ve read on LLM’s. Thank you!
On the topic of AlphaFold, I just wrote this. AlphaFold definitely doesn't understand the physics.
https://clauswilke.substack.com/p/no-alphafold-has-not-completely-solved