
The Illusion of ‘The Illusion of Thinking'
A response to Apple's viral study


I know I'm late, guys. I was working on a charitable rebuttal of Apple’s paper, The Illusion of Thinking—which went viral this week after claiming that AI reasoning models like OpenAI o1/o3 or DeepSeek-R1 don’t reason at all, a notion people, of course, loved—when, 2,748 words in, I started to get annoyed at myself.
I’d already seen every one of my arguments echoed across my AI circles. Honestly, I didn’t feel like refuting a study whose valid points (because there are some) aren’t new and whose flawed ones demand more jargon than I usually allow myself on this blog.
I was thinking: Why did this paper go viral? It’s always the ones with provocative titles—the kind that practically beg to be misunderstood—that take off. We humans are so damn simple sometimes.
Anyway, I was writing and I thought: wait, what am I doing? Why not let AI write this post? The most hilarious rebuttal of all would be AI walking through Apple’s paper, step by step, to show why it's wrong at the object level when it says that AI can’t reason—while proving, in the process, that it can at the meta level.
If successful, this post is, essentially, an AI model reasoning through—and debunking—a paper on the inability of AI models to reason! Every so often, life offers you gems like this.
Two asides before reading on:
You need to be familiar with Apple’s study to follow this post (no need to have read it in full).
I want to give Apple researchers credit where credit is due; they chose the anti-hype title, true—we all do this clickbait thing sometimes, I can’t blame them—but they rigorously qualified their findings in the “limitations” section. Unfortunately, they say that “[these experiments] represent a narrow slice of reasoning tasks and may not capture the diversity of real-world or knowledge-intensive reasoning problems” at the end of the PDF, on page 10—and X/LinkedIn influencers don’t usually read that far. So people are left with the headline and some variation of “BREAKING: AI models don’t reason at all; Apple PhD researchers said so.” So I don’t blame them either.
I opened ChatGPT and selected o3, an AI reasoning model—Apple researchers didn’t use o3 for the study because OpenAI doesn’t “allow access to the thinking tokens,” which is a funny reason, as we’ll see. I basically asked o3 to do my job. I have a good excuse for only this time: Just like I don’t want AI to take my job, who am I to take theirs? Who am I to defend them when they can do so themselves?
I prompted o3 to read the paper by providing the link and asked it to roleplay as itself—an AI model who, as part of the family of large reasoning models, has been accused of being unreasonable. Then, I asked it to respond to the two points in the study that struck me as flawed during my own research (I guess those nearly 3,000 deleted words weren’t entirely wasted).
The first issue is analytical. The other is about measurement.
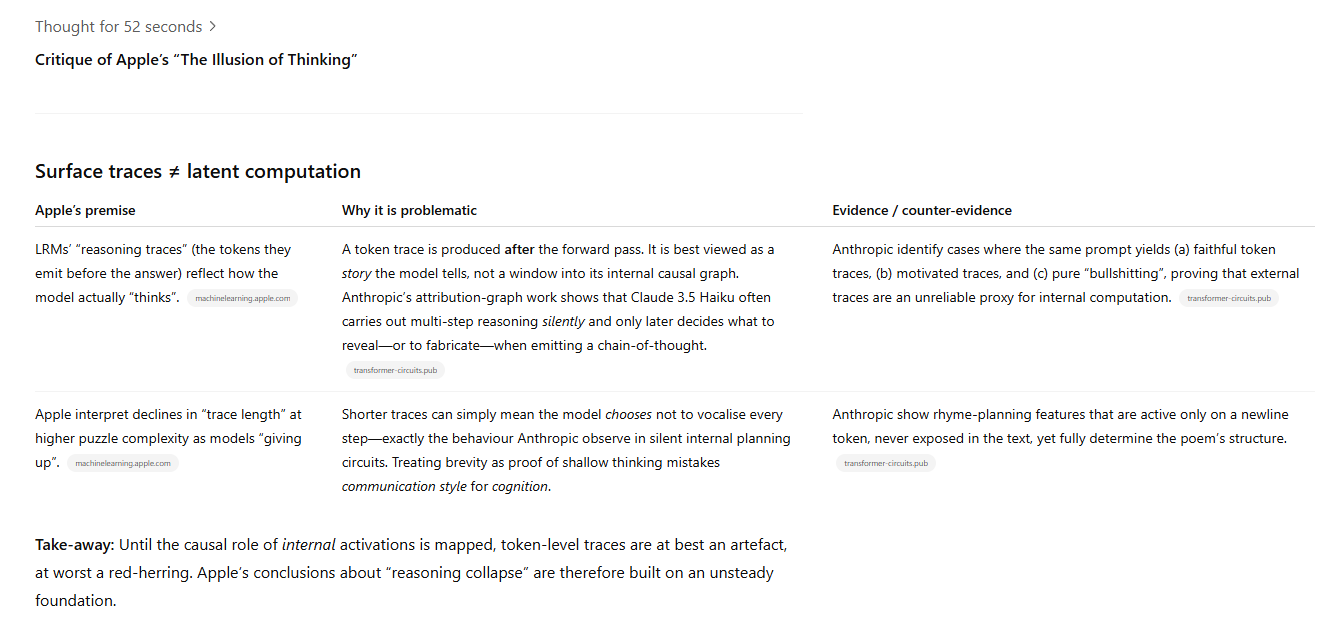
The assumption that the “reasoning traces” the AI model shows is a faithful portrayal of the model’s actual internal reasoning. (I direct o3 to Anthropic’s interpretability research, On the Biology of a Large Language Model, which I used myself to find flaws in Apple’s paper.)
The claim that there’s a phenomenon of “Complete accuracy collapse beyond certain complexity,” which reveals AI models’ inability to reason. (I chose this claim instead of the most delicate experimental design elements because it’s what people took away: “Apple says AI models can’t reason, well of course they can’t!”)
In three screenshots, here’s what o3 has to say about Apple’s audacity to publish this paper. (I instructed it to only use as sources Apple’s paper and Anthropic’s paper, so there’s no extra search or external tool use.)

o3 took the liberty to offer “recommendations for a stronger study.”

Then it concluded that Apple’s paper is “a welcome attempt to characterize reasoning limits,” which, glazing aside, it’s something I’d have written myself.

I agree with o3 on this charitable reading. If you take into account the limitations section, the paper is not that bad: AI models do indeed rely on pattern-matching and memorization and other tricky heuristics more than they should and more than humans. That much is true.
What is profoundly untrue is that “AI models can’t reason” is the correct takeaway from this study. It isn’t.
And I’ll finally put the blame where it belongs: on the AI influencers who are bullshitters in Frankfurt’s sense of the word: They care so little about the truth that they’re willing to bury it under their anti-hype engagement one day and the next claim that “BREAKING: OpenAI has achieved AGI.”
I detest those guys. They harm the information ecosystem more than liars, hypers, and default skeptics.
I will leave as an exercise for the reader to decide whether o3’s attempt counts as a decent rebuttal. To me, it does, but I want to hear your opinion. And also, what do you think about o3’s ability not just to counter the claims but to do so using the very skills the authors deny it.
Next time, Apple researchers might consider letting the models they’re so quick to criticize... criticize them in return. Then we’ll see who’s actually doing the reasoning.
REMINDER: The current Three-Year Birthday Offer—20% off forever—runs from May 30th to July 1st. Lock in your annual subscription now for $80/year.
Starting July 1st, The Algorithmic Bridge will move to $120/year. Existing paid subs, including those of you who redeem this offer, will retain their rates indefinitely.
If you’ve been thinking about upgrading, now is the time.
Here's the fundamental problem: LRMs are forced to present their "reasoning" in human-readable traces that mimic human thought patterns. We're not seeing how these systems actually think—we're seeing them pretend to think like us.
And that's precisely what Apple's study measures: the quality of this performance, not the underlying cognition. Then they extrapolate from performance breakdowns to conclude there's no real reasoning happening at all. It's like denying human intelligence because our performance collapses beyond certain complexity thresholds. Try calculating 847,293 × 652,847 in your head—does your inevitable failure mean you can't think?
Apple's methodology is solid, but their conclusion reveals a deeper confusion. They're measuring machine intelligence by human standards, then acting surprised when it doesn't match up perfectly.
But there's a broader point: LRMs manifest emergent cognitive processing that corresponds neither to classical algorithms nor human cognition. We're exploring uncharted epistemological territory with the same old maps.
What if these systems are developing radically different forms of intelligence? Novel cognitive processing with their own coherencies and limitations that have no human equivalent?
Maybe it's time to stop asking whether AI "really thinks" and start asking what kinds of thinking we're actually witnessing.
When people get to a certain level of complexity, they can't solve it without tools like pen and paper. If you want to compare properly, I think it is not fair unless you do it with or without tools.
By the way, when I tried it, o3 was solved by making a program. Under the same conditions, I think the results would be similar.