
Google Gemini 3 Is the Best Model Ever. One Score Stands Out Above the Rest
Congratulations to the team!


Google has released Gemini 3, the most-awaited model since GPT-5 (the launch includes the Pro version and Deep Think, the reasoning version). Gemini 3 is great, much better than the alternatives—including GPT-5.1 (recently released by OpenAI) and Claude Sonnet 4.5 (from Anthropic)—but I wouldn’t update much on benchmark scores (they’re mostly noise!). However, there’s one achievement that stands out to me as not only impressive but genuinely surprising.
But before I go into that, let’s do a quick review of just how good Gemini 3 is compared to the competition. Google says Gemini 3 has “state-of-the-art reasoning capabilities, world-leading multimodal understanding, and enables new agentic coding experiences,” but when every new model from a frontier AI company is accompanied by the same kind of description, I believe the differences are better understood with images (and, of course, firsthand experience with the models).
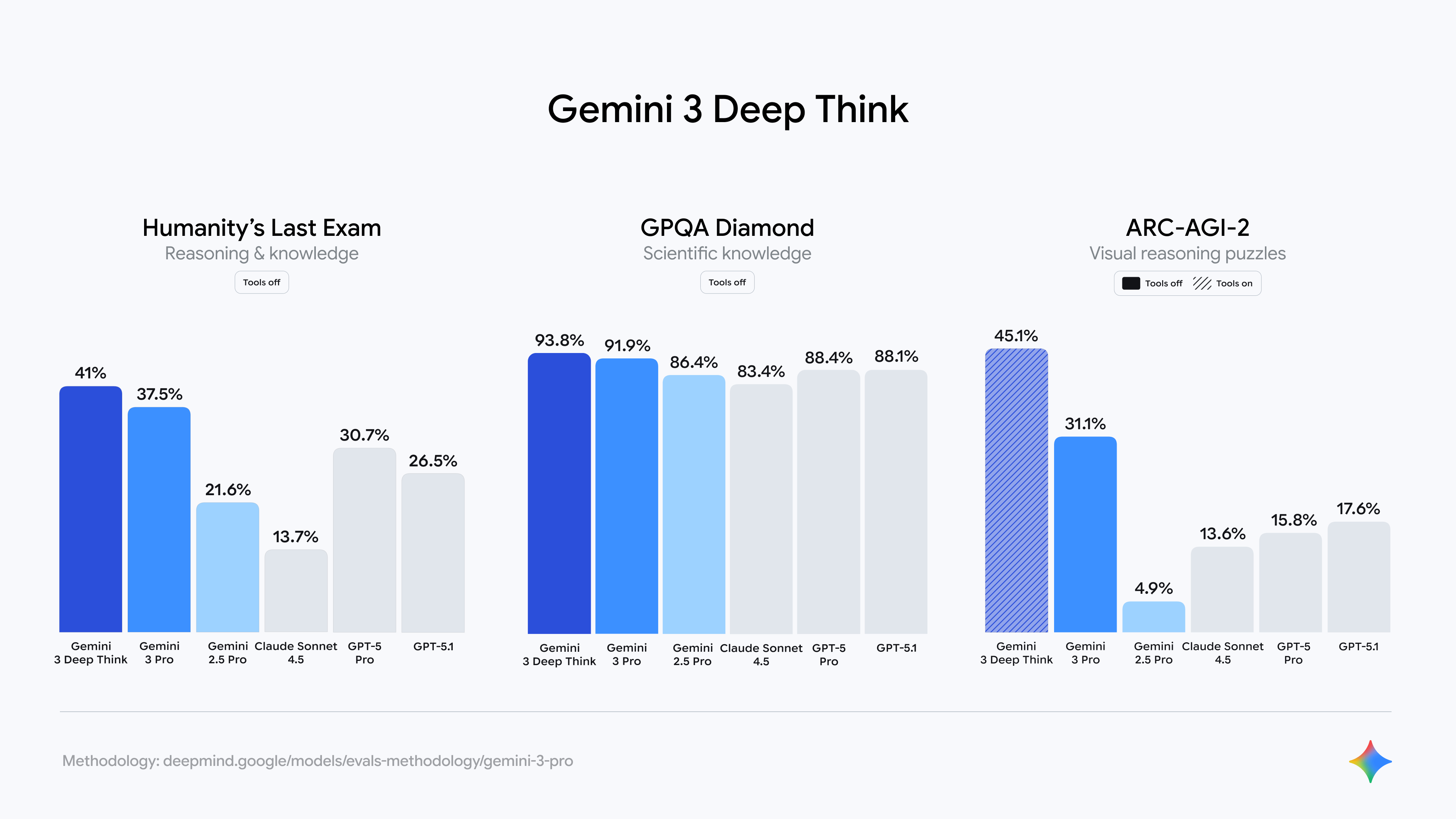
Google tested Gemini 3 Pro against Gemini 2.5 Pro, Claude Sonnet 4.5, and GPT-5.1 (the best models) on 20 benchmarks. It got the top score in 19 of them. Google’s new model dominates in 95% of the tests companies use to measure AI’s skill. Crazy:

Look at that bolding. Some notable mentions:
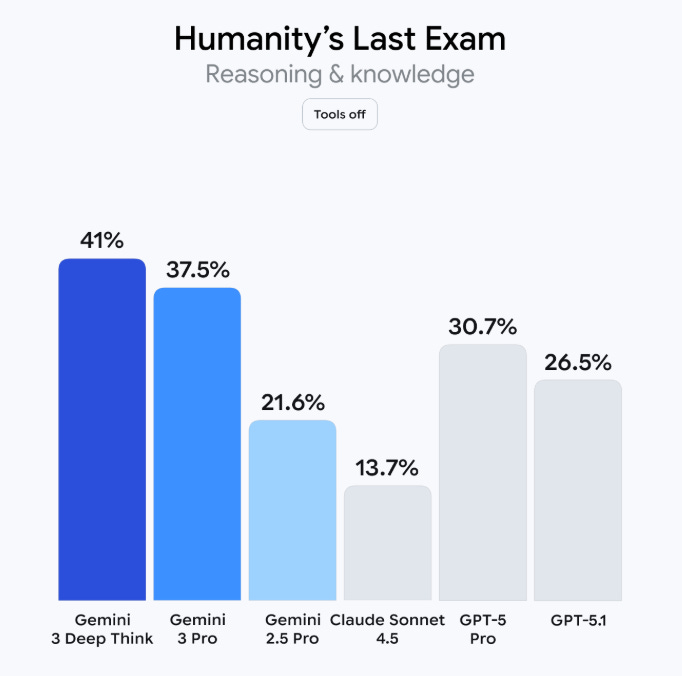
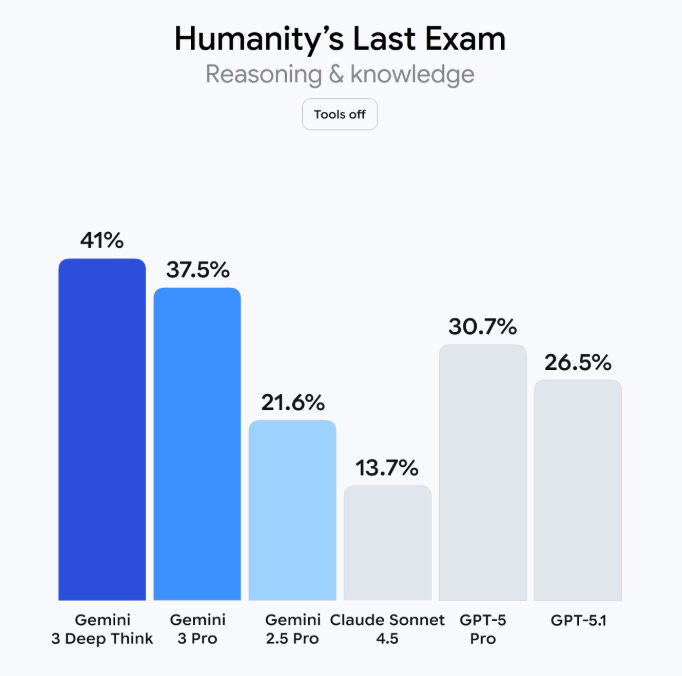
Gemini 3 Pro achieved an 11 percentage-point jump on Humanity’s Last Exam (a benchmark consisting of “2,500 challenging questions across over a hundred subjects”), up to 37.5% from GPT-5.1’s 26.5%.
Source: Google Gemini 3 Pro earned ~$5.5k on Vending-Bench 2, the vending machine benchmark (it tries to answer a valuable real-world question: Can AI models run a profitable business across long horizons?), compared to ~$3.8k from Sonnet 4.5.
Source: Google There’s a ~40% gap between Gemini 3 Pro and the competition in SimpleQA Verified, a factuality benchmark that measures how well AI models answer simple fact-checking questions (important for hallucinations).

Source: Google DeepMind Gemini 3 Pro got first place in the Artificial Analysis Intelligence Index (comprising 10 different evaluations; it came first in five), three points above the second-best model, OpenAI’s GPT-5.1: it’s the largest gap in a long time.

Source: Artificial Analysis



I usually dislike benchmarks as a measure of quality or reliability, or intelligence—my stance on the topic can be summarized by this: “how well AI does on a test measures how well AI does on a test”—but it’s hard to deny that whatever it is that these tests collectively measure (I believe there’s some degree of correlation between, say, a software engineering test and a model’s ability to solve software engineering tasks in the real world), Google is the undisputed leader.
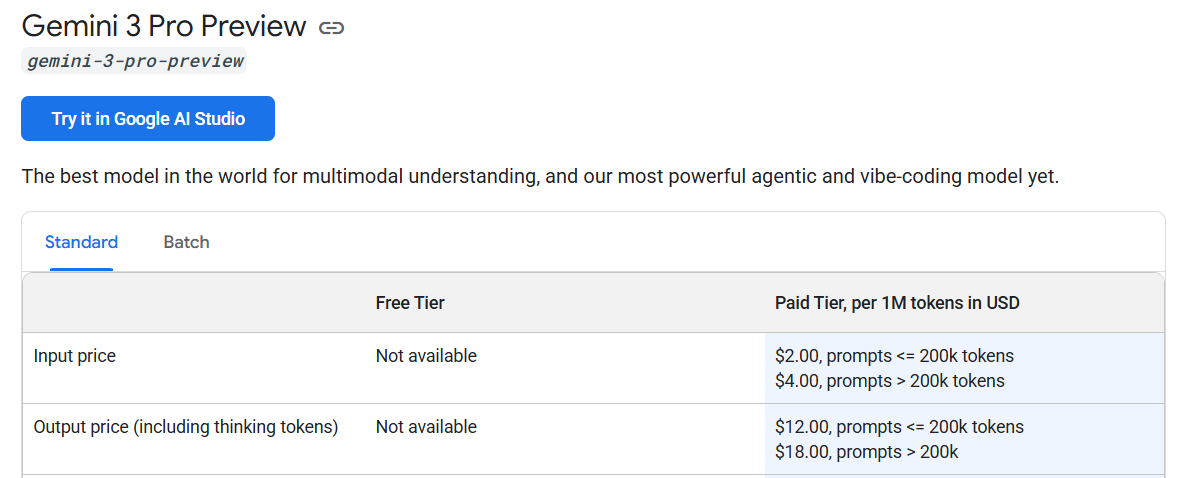
One important detail for those of you using the API is that Gemini 3 is rather expensive compared to most other options, although it remains faster than most.
There are plenty of things that Gemini 3 does better than other models that are hard to capture with benchmarks or images. Google mentions that Gemini 3's agentic mode “can autonomously plan and execute complex, end-to-end software tasks simultaneously on your behalf while validating their own code.”
Or that, “By combining deeper reasoning with improved, more consistent tool use, Gemini 3 can take action on your behalf by navigating more complex, multi-step workflows from start to finish — like booking local services or organizing your inbox — all while under your control and guidance.”
Or that “Gemini 3 can decipher and translate handwritten recipes in different languages into a shareable family cookbook. Or if you want to learn about a new topic, you can give it academic papers, long video lectures or tutorials and it can generate code for interactive flashcards, visualizations or other formats that will help you master the material.”
To me, that sounds like marketing-speak (accompanied by nice marketing visuals). You have to test it for yourself and figure out—in case you’re a customer of some other AI provider—whether Gemini 3 significantly improves over other services. In most cases, whatever model you’re already using is probably just fine. It is increasingly the case that only power users, scientists, enterprises, etc., will need to update on new AI releases. But let’s keep going. There are still a few more things I want to share.
Some technical details from the model card: Gemini 3 is not built upon a previous model; it is, like Gemini and Gemini 2, natively multimodal; it’s a sparse mixture-of-experts (the industry standard); it accepts up to 1 million tokens of input (64K output); it was trained exclusively with Google’s own hardware (TPUs); and there’s not much information about the data besides the usual (readily available + licensed sources).
But none of the above is as impressive as the thing I wanted to highlight as the clearest signal that Gemini 3 is something else:
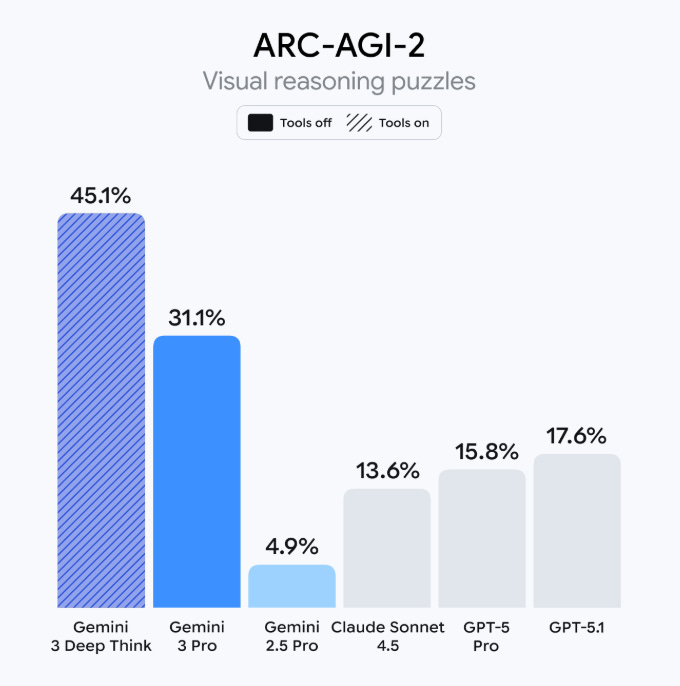
Gemini 3 Pro and Gemini 3 Deep Think achieve an incredible 31.1% and 45.1% on ARC-AGI 2, respectively. The gap between Gemini 3 and the rest is just ridiculous: 2x for Gemini 3 Pro and 3x for Gemini 3 Deep Think. Look at the graphs:
{kind=link}

For comparison, GPT-5.1 Thinking (High)—the next highest model—got 17.6% on ARC-AGI 2 ($1.17/task, compared to Gemini 3’s 31.$0.81/task; better and cheaper).
Don’t confuse this gap with the usual new-model-is-better jump in capabilities: look at the level of clustering among the other models; there are years of progress piled up between 0% and 15%. And then, there comes Google, reaching 45%. That’s just crazy; you don’t see a 3x leap in percentage points in an AI benchmark these days.
We don’t know what Google cooked to get this score, but there are a few things we can conclude from this result on ARC-AGI 2 (on top of the other benchmarks):
I am right that Google is winning the race.
It’s not good to over-index on any benchmark (including ARC-AGI 2), but there’s a lot of signal in a new model 2-3xing a benchmark that’s designed specifically to be easy for humans and hard for AIs. ARC-AGI requires more fluid intelligence rather than crystallized intelligence (to use François Chollet’s terminology), which is the kind AI models struggle with.
ARC-AGI (1 and 2, it doesn’t matter) feels extremely easy to me compared to most of the other benchmarks. The fact that AI struggles with them is interesting, but the fact that Gemini 3 Pro can achieve 30%+ and still fail some easier ARC-AGI 1 tasks is dumbfounding: it reveals just how alien AI’s intelligence is to us (who design these tests thinking we understand what “easy” and “hard” mean for AI models) and how unfamiliar—and jagged—its failure modes are.
Mike Knoop, co-founder of ARC Prize, said that “We’re also starting to see the efficiency frontier approaching humans.” Gemini 3 Pro, at its fastest, is nearing the average speed of humans, which is surprising because we operate visually on ARC-AGI, whereas AI models use tokens as they normally would.
Celebrating scores of <50% is only reasonable in the context of AI generally struggling a lot with this test, but in no way does a 50% seem sufficient to claim victory, nor is it anywhere close to matching the average human performance (much less top performance, which AI easily surpasses in most of the other tests). (Google “killed it” but didn’t beat it.)
Knoop also notes that the tasks Gemini 3 Deep Think fails in ARC-AGI 1 seem to “have relatively large grid sizes compared to the solved tasks.” This reminds me of a particularly insightful criticism of ARC-AGI as a benchmark that argued it’s measuring not so much fluid intelligence as the ability to hold a lot of information in the context window (and that’s why larger sizes have a higher probability of failure). I’d love to see ARC-AGI 3 vindicated in this regard.
Finally, the fact that companies are increasingly more incentivized to destroy whatever benchmark is left to be destroyed, and yet they remain unable to beat ARC-AGI, is growing evidence that this one is actually Goodhart-proof: despite this measure being targeted by AI companies, it doesn’t cease to be a good measure.
I’m curious to see how Gemini 3 Pro performs on ARC-AGI 3. I tried it myself and, while a bit more convoluted than the previous two versions, it’s still fairly manageable. Most of the other benchmarks feel irrelevant now; companies have trained their models specifically to ace them, knowing that’s what the community watches. But ARC-AGI remains a tough nut to crack.
I’m glad at least one company seems to be narrowing the gap between machine superintelligence and us dumb humans. (Ha!) In case you’re curious about how Google achieved such a sweeping victory, let me paraphrase Oriol Vinyals, VP of Research at Google DeepMind: the “secret behind Gemini 3” is simple—
—they improved everything.
As shown on the screenspot pro benchmark, Gemini seems to be better than the other LLMS at image understanding. I think this is why it’s good at ARC. Even though you feed the LLMs ARC1 in text, the visualisation helps. Like when I see the puzzles it becomes a lot easier, so maybe, by allowing Gemini a better ‘visual brain’ it also does better.
As far as I know nano-banana is the best AI image generators/editor. AND Google is doing interesting video -> playable-world stuff. My theory is that they have figured out a way for better knowledge transfer between these models rather than just bolting image models and LLMS together.
One other question that stands out is how is Anthropic still so good at coding? Even with all these advances anthropic stays ahead in coding benchmarks and often seems to be the preferred choice for developers.
I recall you speculated this would happen quite some time ago in your posts