
OpenAI o3-Pro Is So Good That I Can’t Tell How Good It Is
The downsides of not being a world-class mathematician


Let’s play a game. You have only one question: What do you ask to distinguish between the best mathematician in the world and a member of the 0.001% class of mathematicians?
Think the problem through before reading on. It won’t take you much to reach the correct answer.
Truth is, this isn’t a riddle, dear reader—there is no such question. Nothing you can ask will reveal the difference between Mr. number 1 and Mr. number 1,000. Their knowledge and skill are beyond you to such a degree that they are the same.
Oh, but I’m assuming too much. Perhaps you are a genius mathematician after all. So let me clarify what I mean: Only if you belong somewhere between the 0.001%—around top university professor level—and the likes of Gauss, Euler, Riemann, Fermat, Poincaré—depending on when you're traveling from—could you find The Question.
The odds are surely against us. We're 37,000 on this blog, yet 0.001% is one in a million. And Terence Tao is taken. So, most likely, neither you nor me are clever or knowledgeable enough.
If you think about it, it’s easy to find a question both #1 and #1,000 can answer, and also easy to find a question that both cannot answer (what’s the solution to the Riemann hypothesis or P vs NP; the kinds of problems that no one has yet solved).
But how to tell them apart? No clue.
Now that it’s pretty clear how hard it is to distinguish an absolute genius from an absolute almost-genius, I will introduce you to today’s topic: This problem is, increasingly, like distinguishing between the best AI model in the world and the second-best model.
OpenAI just announced o3-pro.
There's no doubt that it is the best AI model in the world.
But how am I so sure? How are they so sure?
Evals and benchmarks barely work; most are saturated (some aren’t, and we should pay more attention to those). We can hardly come up with a sufficiently large number of questions to separate their skills with statistical significance. This is how o3-pro vs o3 looks in math, code, and science:
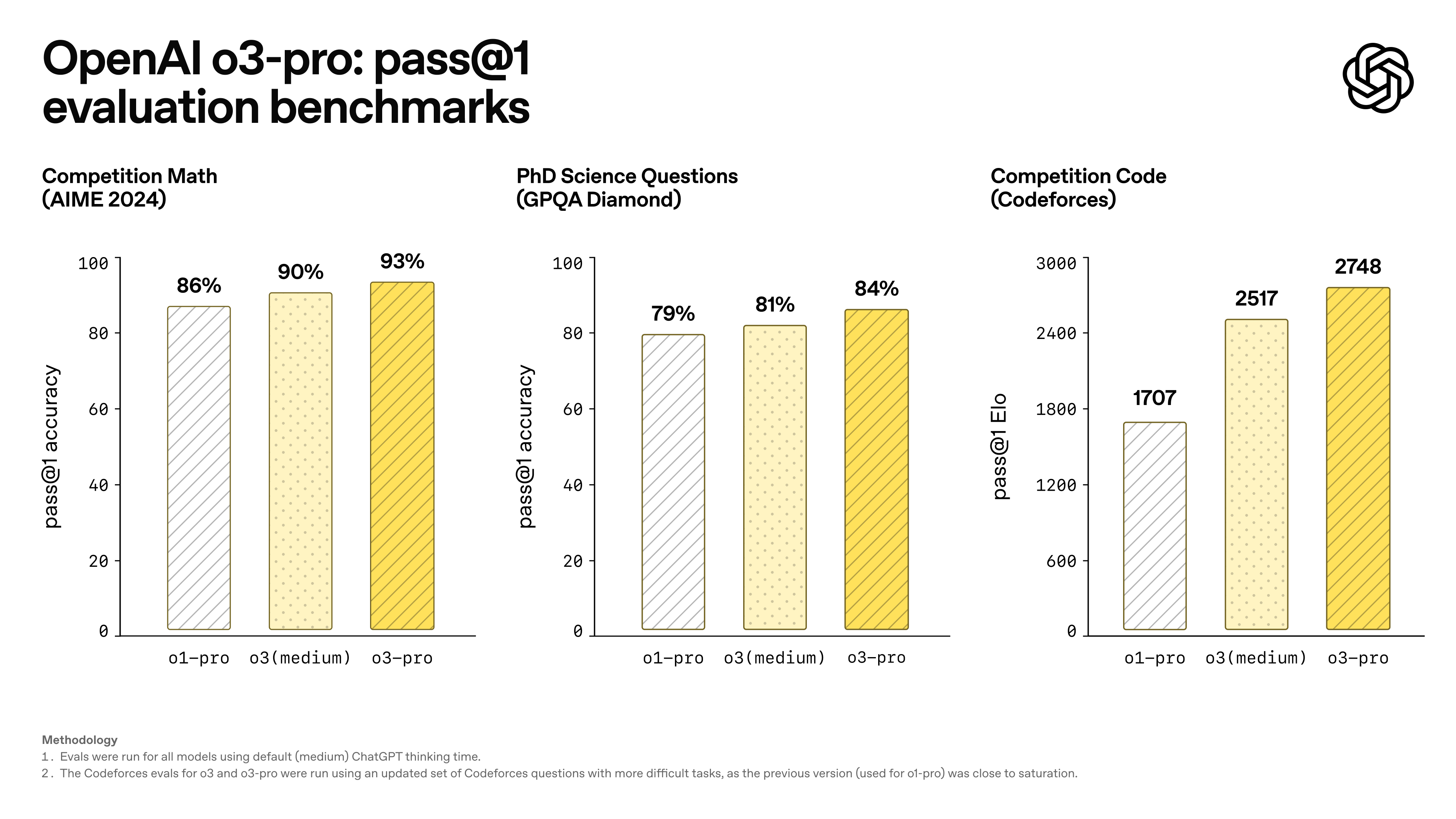
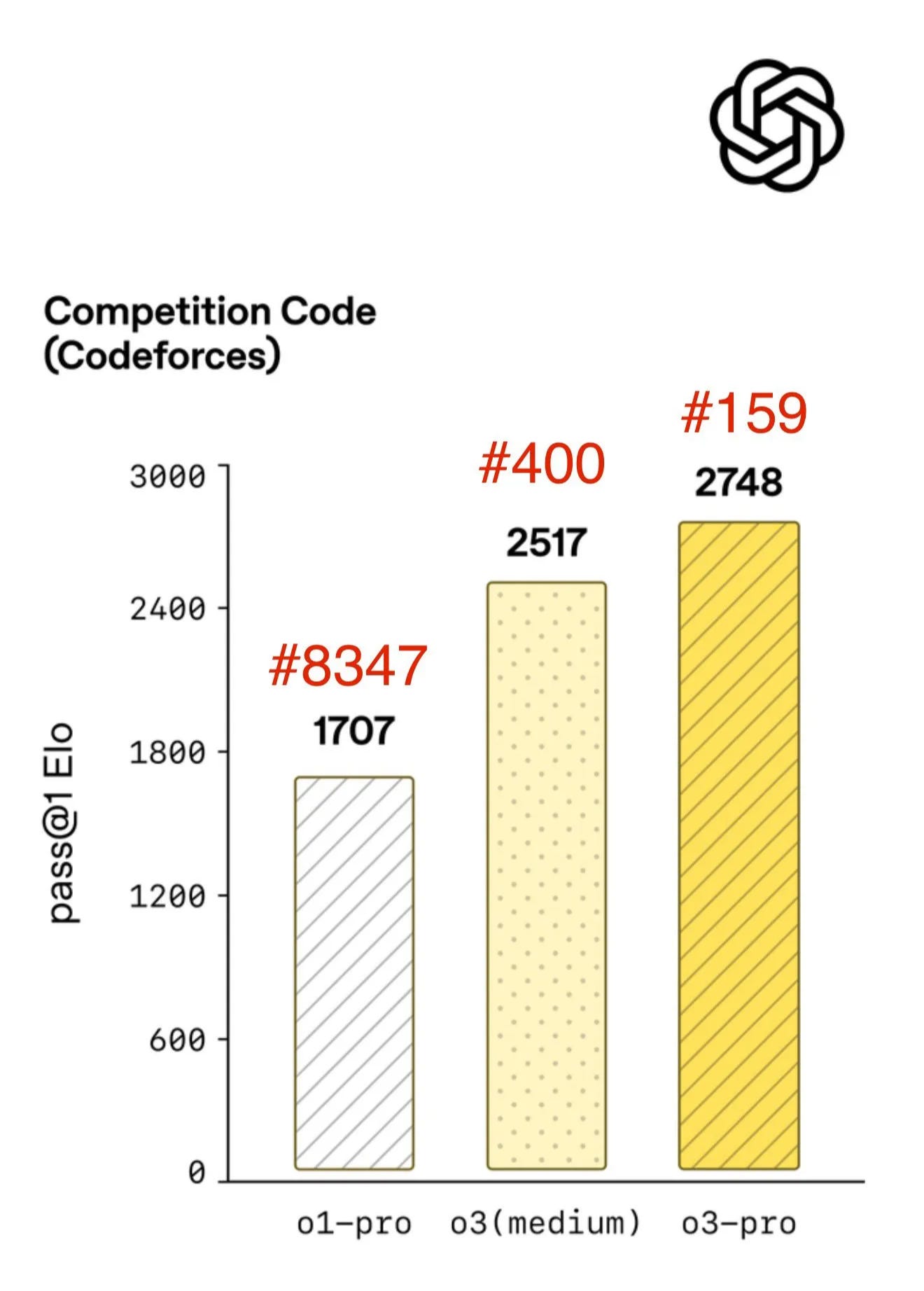
At a competition math level, the difference between 90% and 93% is negligible. At the competition code level, 2517 ELO corresponds to the #400 human and 2748 ELO to the #159 human. Can you differentiate them? We are already not that far from facing the thought experiment I made up above.
OpenAI, Google, Anthropic, and Co. are seeking world-class mathematicians to come up with hard enough questions that top AI models can’t solve. And they’re having trouble with the task.
So, how do you consistently tell that o3-pro is better than o3? Vibes and taste. Oh, no. That again.
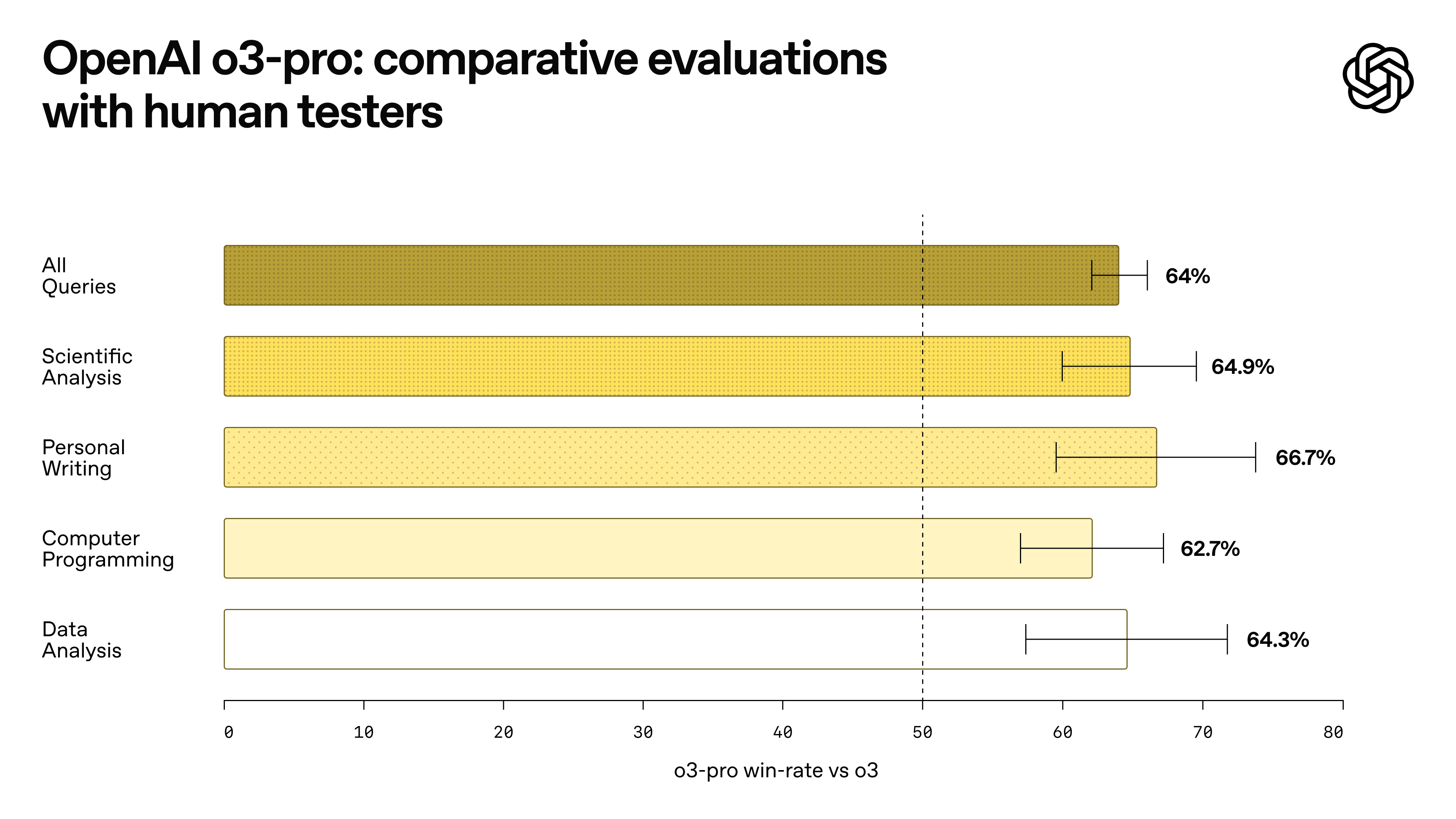
This is human testers preferring o3-pro vs o3 across tasks by a significant margin. They may not even be able to tell why they prefer one or the other. Unless they are at a sufficiently high level.
Let's see how well I’d fare. Math? Way over my head. Code? Ha!—I wouldn't be a writer. Physics? I stopped at thermodynamics. And writing—which you could say is the thing I'm best at despite not being traditionally trained on it and clearly not successful because I have yet to be a New York Times bestselling author—is not an adequate testing ground (despite OpenAI insisting on it).
o3-pro is pushing us into uncharted territory.
Eventually—and not too long from now—no human except perhaps the absolute best in their fields will be able to act as evaluators of AI models. Beyond that point, AI models will become the best at doing the tasks and the best at evaluating how well AI models do the tasks.
Humans. out. of. the. loop.
IMPORTANT REMINDER: The current Three-Year Birthday Offer—20% off forever—runs from May 30th to July 1st. Lock in your annual subscription now for $80/year.
Starting July 1st, The Algorithmic Bridge will move to $120/year. Existing paid subs, including those of you who redeem this offer, will retain their rates indefinitely.
If you’ve been thinking about upgrading, now is the time.
This post was inspired by Ben Hylak’s writing on Latent Space. (To give you some credentials: he worked at SpaceX, then Apple, and now owns an AI company as a partner to OpenAI, Google, and Anthropic.) He said something about his testing of o3-pro vs o3 that struck me:
[o3-pro] is smarter. much smarter.
But in order to see that, you need to give it a lot more context. and I’m running out of context.
There was no simple test or question i could ask it that blew me away.
o3-pro is not there yet—he managed to get it to show its superior prowess:
But then I took a different approach. My co-founder Alexis and I took the the time to assemble a history of all of our past planning meetings at Raindrop, all of our goals, even record voice memos: and then asked o3-pro to come up with a plan.
We were blown away; it spit out the exact kind of concrete plan and analysis I’ve always wanted an LLM to create — complete with target metrics, timelines, what to prioritize, and strict instructions on what to absolutely cut.
The plan o3 gave us was plausible, reasonable; but the plan o3 Pro gave us was specific and rooted enough that it actually changed how we are thinking about our future.
This is hard to capture in an eval.
There’s still a way, if you have a complex enough problem with enough context so that it’s not skill or knowledge that differentiates one model from another, but their ability to take on agent-level tasks.
But by Ben’s reaction to o3-pro—”it actually changed how we are thinking about our future”—it’s quite clear he will be getting out of complex enough problems soon enough.
“This is hard to capture in an eval,” he says.
So, dear reader, we are alone out there, charting this wild territory.
What can we do as normal people with normal skills? Curate our trust. We are left delegating, once again, the ability to get a state-of-the-art picture of AI’s skills. As we get closer to AGI—or whatever next milestone strikes your fancy—this will only become more apparent.
Welcome to the event horizon. (I thought of the “event horizon” phrase before Sam Altman published his blog post!)
But, wait.
Keep reading with a 7-day free trial
Subscribe to The Algorithmic Bridge to keep reading this post and get 7 days of free access to the full post archives.